Rust (1.48.0) で独自のスライス型や文字列型を定義する
Rust でプログラムを書くうえで、用途や制約に応じた適切な型の定義は大変重要である。
たとえば Rust ではバイト列は [u8]、 UTF-8 文字列は str、OS ネイティブのエンコーディングの文字列は std::ffi::OsStr、パス文字列は std::path::Path といったように、横着すればひとつの型で済むような様々なデータに対してそれぞれの特徴に応じた型を標準で用意している。
ときに標準ライブラリで用意された型ばかりでなく、自分で専用の型を用意したいこともある。
たとえば「相対パスのみを保持できる型」のようなものを実装したくなるかもしれない。
もちろん Rust でこれは可能なのだが、 str のような (値として利用するときは &str のように参照を使う) 可変長のスライスのような型は、定義したり十分な利便性を確保するのに多少のコツが必要となる。
本記事では、独自のスライス型や関係する定義の方法や理由について、実際に動く例を挙げて詳細に解説する。
なお、この記事は CC-BY 4.0 ライセンスで、記事中のソースコードは (本記事の筆者以外によるプロジェクトからの引用を除いて) CC0 1.0 ライセンスで提供される。
この記事は Rust 2 Advent Calendar 2020 の23日目[0]の記事である。
準備と前提知識
strong typedef
スライス型を自前定義する意義を考えるうえで、まず strong typedef というテクニックについて説明せねばなるまい。 strong typedef について十分知っている読者は、このセクションを丸々読み飛ばして問題ない。
本来なら C++ あたりのコード例で説明するところだが、この記事は Rust での手法について説明するものなので例も Rust で書くことにする。
C や C++ での typedef に相当するものは、 Rust では type である[1]。
typedef
前提として、 typedef とはC言語や C++ で型に別名を与える構文のための予約語である。
typedef は本当に別名を用意するだけで、その性質や扱いに変化を与えることはない。
純粋に可読性のための存在といえる。
/// A type for an array index.
type ArrayIndex = usize;
fn main() {
let i0: usize = 42;
// `ArrayIndex` and `usize` are identical.
let i1: ArrayIndex = i0;
let _i2: usize = i1;
}
type (C や C++ での typedef) は型に別名を与えるだけで、その性質には変化を与えないため、 usize の変数と ArrayIndex の変数は同じ型を持つものとして扱われる型の性質に変化を与えないため挙動は理解しやすいが、反面 typedef は新しい型を作る用途で使うことはできない。 あくまで別名を割り当てるだけである。 つまり、本来禁止したかった用法や無意味な計算が許されかねないということである。
/// A type for an array index.
type ArrayIndex = usize;
fn main() {
let i0: ArrayIndex = 1;
let i1: ArrayIndex = 2;
// What does this mean?
let _sum: ArrayIndex = i0 + i1;
// Nonsense!
let _nonsense: ArrayIndex = i0 * !i1;
}
ArrayIndex 型に対して usize から引き継いだ演算が全て使えてしまう
/// A type for an array index.
type ArrayIndex = usize;
/// A type for distance between array elements.
type ArrayDistance = usize;
fn main() {
let i0: ArrayIndex = 42;
let i1: ArrayIndex = 314;
// Meaningful.
let _distance: ArrayDistance = i1 - i0;
// Nonsense. Array index is offset from the beginning,
// but not distance between arbitrary elements.
let _nonsense: ArrayIndex = i1 - i0;
}
こうして「既存の型をもとにして (つまり内部表現を同一にして) 用途特化型を楽に定義したい」という夢は潰えた。 夢破れた人々がそれでも諦められない場合に使うのが strong typedef である。
strong typedef の違いと例
strong typedef とは、内部的には既存の型を使って、それでも元の型と互いに区別されるような用途特化型を定義しようという手法である。 例を見た方が早かろう。 strong typedef は Rust では以下のように (あるいは他言語でも似たような方法で) 実現される。
use std::{cmp, ops};
/// A type for an array index.
#[derive(Debug, Clone, Copy, PartialEq, Eq, PartialOrd, Ord, Hash)]
struct ArrayIndex(usize);
impl ArrayIndex {
pub fn new(i: usize) -> Self {
Self(i)
}
pub fn to_usize(self) -> usize {
self.0
}
}
/// A type for distance between array elements.
#[derive(Debug, Clone, Copy, PartialEq, Eq, PartialOrd, Ord, Hash)]
struct ArrayDistance(usize);
impl ArrayDistance {
pub fn new(i: usize) -> Self {
Self(i)
}
pub fn to_usize(self) -> usize {
self.0
}
}
// index + distance => index.
impl ops::Add<ArrayDistance> for ArrayIndex {
type Output = Self;
fn add(self, distance: ArrayDistance) -> Self::Output {
Self(self.to_usize() + distance.to_usize())
}
}
// index - distance => index.
impl ops::Sub<ArrayDistance> for ArrayIndex {
type Output = Self;
fn sub(self, distance: ArrayDistance) -> Self::Output {
Self(self.to_usize() - distance.to_usize())
}
}
// index - index => distance.
impl ops::Sub<ArrayIndex> for ArrayIndex {
type Output = ArrayDistance;
fn sub(self, other: ArrayIndex) -> Self::Output {
let min = cmp::min(self, other);
let max = cmp::max(self, other);
ArrayDistance::new(max.to_usize() - min.to_usize())
}
}
fn main() {
let i0: ArrayIndex = ArrayIndex::new(42);
let i1: ArrayIndex = ArrayIndex::new(314);
let d0: ArrayDistance = i1 - i0;
let d1: ArrayDistance = i0 - i1;
assert_eq!(d0, d1);
// ERROR.
//let _sum_meaningless = i0 + i1;
// ERROR.
//let _product_meaningless = i0 * i1;
// If you really really want the product, you can do this.
let _product = i0.to_usize() * i1.to_usize();
}
このコードは正直微妙なところがあるが[2]、例としては十分だろう。
typedef では混同できていた index と distance が strong typedef では区別されており、混同するとコンパイルが通らない。
typedef では添字同士の乗算などの一般に意味のない演算ができてしまったが、 strong typedef ではそのような演算はできない。
このように、 strong typedef は次のような方法によって型を定義する手法のことである。
-
デフォルトでは他の型から暗黙に変換できないような型を作る。 C, C++, Rust では struct を作るのが一般的。
- 通常この構造体はメンバ変数 (あるいはフィールド) をひとつだけ持ち、その型がベースとなる既存の型である。
-
新たな型の値を作る方法を用意する。
新たな型とベースとした型との間で相互に変換できるよう関数を用意するのが一般的。
- ただし、暗黙の型変換などを迂闊に実装しないよう注意すること。
-
新たな型について、意味のある演算子や関数などを実装する。
内部実装としては、ベースとした型での演算をそのまま再利用するのが一般的。
-
たとえば
f64をベースにした時刻型であれば、時刻同士の減算には意味があるが、加算や乗算、除算には意味がない。 このような場合には時刻同士の減算演算子だけを定義し、内部的にはf64の減算を使う。 ただし、戻り値の型は時刻 (time point) ではなく時間 (duration) となるだろう。
-
たとえば
strong typedef は極めて応用範囲の広い手法だが、たとえば以下のような利用例が考えられる。
-
物理量の区別
- 質量と距離はともに実数だが、これらを足したり混同するのは無意味なので禁じたい。
-
バイト列と UTF-8 文字列の区別
- 両者はともにバイト列で表現可能だが、任意のバイト列が常に正しい UTF-8 文字列とは限らない。 別の言い方をすると、 UTF-8 文字列はバイト列の部分集合である。
-
大文字・小文字を区別しない文字列型の定義
- ほとんどの場合通常の文字列として振る舞うが、比較時だけ大文字と小文字を同一視するような文字列型が欲しい場合がある。
-
ASCII 文字しか持てない文字列型の定義
- ほとんどの場合通常の文字列として振る舞うが、 ASCII 文字しか持てないよう制約を加えた文字列型が欲しい場合がある。
スライス型
スライス型と DST についても説明しておこう。
Rust においては [T] や str 、 std::path::Path のように、値そのもののサイズ (長さ) が不定な型が存在する。
これらを DST (Dynamically Sized Types) と呼ぶ。
こういった型は &[T] や &str のように参照型を通して扱うことになるが、これらの参照型をスライス型と呼ぶ[3]。
スライス型の値 (すなわち参照) は低レベルで表現されるとき単なるポインタではなく、ポインタと長さの組である[4]。
A dynamically-sized view into a contiguous sequence, [T].
DST はサイズ不定であるゆえ、通常の型とは扱いが異なる。 典型的には、(少なくとも現状 (Rust 1.48.0) では[5])参照でない生の値として扱えないなどの制限がある。
fn main() {
let s: str = *"foo";
}
Compiling playground v0.0.1 (/playground)
error[E0277]: the size for values of type `str` cannot be known at compilation time
--> src/main.rs:2:9
|
2 | let s: str = *"foo";
| ^ doesn't have a size known at compile-time
|
= help: the trait `Sized` is not implemented for `str`
= note: all local variables must have a statically known size
= help: unsized locals are gated as an unstable feature
error: aborting due to previous error
For more information about this error, try `rustc --explain E0277`.
error: could not compile `playground`
To learn more, run the command again with --verbose.
このように特殊な性質を持つ DST は、定義やメソッド定義、トレイト実装等に注意や工夫が必要であるため、本記事ではそれらを紹介する。
2種類の独自スライス型
本質的に大した差ではないが、お気持ちのうえで、また実装や設計のうえで独自スライス型は2種類に分類できる。 ひとつは、情報の欠落なしに元となる型と相互に変換できる、追加の制約なしの型。 もうひとつは、相互の変換で情報の欠落があったり、変換の失敗がありえるような、追加の制約付きの型である。
たとえば str は「[u8] で表現可能なバイト列のうち、 UTF-8 バイト列として妥当なもの」という追加の制約付きの型である。
&str の値は無条件に &[u8] に変換可能であるが、逆は失敗する可能性がある。
対照的に、 std::path::Path と std::ffi::OsStr が表現可能な情報の範囲は低レベルにおいては相互に等価であり、 AsRef を通して失敗と欠落なしに相互に変換できる。
std::ffi::OsStr 自体がとりうる値には制約があるが、これを std::path::Path へと変換する際に追加の制約を与えられることはない。
本記事では、これらの2種類の型の例として、 str を追加の制約なしに strong typedef した MyStr と、「ASCII 文字しか持っていない」という追加の制約付きの AsciiStr および AsciiBytes 型を用いる。
また、これらに対応する所有権付きの型 (たとえば str に対する String) として、 MyString 型と AsciiString および AsciiByteBuf 型も定義していく。
スライス型の定義
型定義の時点では、追加の制約の有無は基本的に関係ない[6]。
/// My custom string slice type.
#[derive(PartialEq, Eq, PartialOrd, Ord, Hash)]
#[repr(transparent)]
// Comparisons implemented for the type are consistent (at least it is intended to be so).
// See <https://github.com/rust-lang/rust-clippy/issues/2025>.
#[allow(clippy::derive_hash_xor_eq, clippy::derive_ord_xor_partial_ord)]
pub struct MyStr(str);
/// ASCII string slice type.
#[derive(PartialEq, Eq, PartialOrd, Ord, Hash)]
#[repr(transparent)]
// Comparisons implemented for the type are consistent (at least it is intended to be so).
// See <https://github.com/rust-lang/rust-clippy/issues/2025>.
#[allow(clippy::derive_hash_xor_eq, clippy::derive_ord_xor_partial_ord)]
pub struct AsciiStr(str);
/// ASCII string slice type.
#[derive(PartialEq, Eq, PartialOrd, Ord, Hash)]
#[repr(transparent)]
// Comparisons implemented for the type are consistent (at least it is intended to be so).
// See <https://github.com/rust-lang/rust-clippy/issues/2025>.
#[allow(clippy::derive_hash_xor_eq, clippy::derive_ord_xor_partial_ord)]
pub struct AsciiBytes(str);
AsciiStr と AsciiBytes の違いは、前者が文字列との相互運用のみを前提とする単純な実装で、後者は文字列のみならずバイト列との相互変換などが扱える点である。
利便性で考えれば後者が良いが、実装が若干煩雑になる箇所もある。
よって、本記事では単純な実装で誤魔化すこともできるよう、両方のコード例を提示する。
struct
型自体は struct で定義する。 例では単要素の tuple struct としたが、フィールドをひとつしか持たない通常の構造体で定義してもよい。
/// My custom string slice type.
#[derive(PartialEq, Eq, PartialOrd, Ord, Hash)]
#[repr(transparent)]
pub struct MyStr {
inner: str,
}
この辺りは純粋に好みの問題である。
derive
#[derive(PartialEq, Eq, PartialOrd, Ord, Hash)]
基本的に derive は何事もなく利用できるが、定義している型が DST であるゆえ、 Self が必要になるトレイトは使えないことに注意が必要である。
具体的には、 Default, Clone トレイトではメソッドの戻り値に Self が使われているため実装できず、 Copy トレイトも Clone を前提としているため同じく実装できない。
よって独自スライス型で derive 可能なトレイトは Debug, PartialEq, Eq, PartialOrd, Ord, Hash である。
無論、これらのトレイトは実装せずともよいし、 derive せず自分で impl しても良い。
たとえば「比較時に大文字と小文字が区別されない文字列型」などを作ろうとしたとき、 PartialEq や PartialOrd を derive せず手書きで実装することになるだろう。
// Comparisons implemented for the type are consistent (at least it is intended to be so).
// See <https://github.com/rust-lang/rust-clippy/issues/2025>.
#[allow(clippy::derive_hash_xor_eq, clippy::derive_ord_xor_partial_ord)]
これは最悪体験なのだが、 Hash と PartialEq の組や Ord と PartialOrd の組で一方を derive して一方を手動で実装すると、 clippy に deny で叱られる。
これは #[derive(PartialEq, Hash)] していても別の型への PartialEq 実装があると叱られるという最悪の実装なので、無効化するしかない。
一応 false positive の問題として上流で認識されてはいるので、そのうち改善されることが期待できる。
#[repr(transparent)]
#[repr(transparent)]
これが型定義で最も重要な部分である。
#[repr(..)] は型の内部表現についての指定をコンパイラに与えるものであり、たとえば「特定のアラインメントを持たねばならない」や「C言語における構造体と同等のメモリレイアウトを持たねばならない」などの指定ができる。
#[repr(transparent)] の意味は、「定義しようとしている型は、その内部の (ZST でない) 型と同じメモリレイアウトを持つ必要がある」といったところである。
この指定は未定義動作を防ぐために不可欠なものであり[7]、決して忘れてはいけない。
なぜ #[repr(transparent)] が必要か
#[repr(transparent)] の欠如が未定義動作を引き起こす理由を理解するには、型のメモリレイアウトを考える必要がある。
たとえば &str と &MyStr を例に考えよう。
&str は、低レベルでは文字列の長さ(バイト長)と先頭文字へのポインタの組として考えることができる。

ところが、 #[repr(transparent)] なしに struct MyStr(str); とした場合、 &MyStr のメモリレイアウトは &str と同じであるとは保証されない。
/// My custom string slice type.
// Note that no `#[repr(transparent)]` is specified.
#[derive(Debug, PartialEq, Eq, PartialOrd, Ord, Hash)]
pub struct MyStr(str);



&MyStr の内部レイアウトは &str と同じかもしれないし、違うかもしれない。
保証されている性質はごく僅かであり、ここでは役に立たない。
これで何が困るかというと、参照型の AsRef や Deref による型変換が安全に行えなくなってしまうのである。
たとえば &str を str::as_bytes() で &[u8] 型の参照にすることができるが、これは &str と &[u8] のメモリレイアウトが一致しているからこそ可能である。
参照型を変換するとき、「0xff000000 から 8 バイトの文字列を、 0xff000000 から 8 バイトの u8 の配列と見做す」という解釈の切り替えが発生しているのである。
![&[u8] 型の値の例](u8-slice-layout-and-value.svg)

&[u8] と &str のメモリレイアウトは一致しているため、「&str の値をあたかも &[u8] の値であるかのように解釈する」ことができる
しかし、メモリレイアウトが一致していない場合、この解釈の切り替えが不正な操作となってしまう。
たとえば &str がポインタの後に長さを持っているとして、しかし &MyStr が長さの後にポインタを持っているとする。
このような状況で&MyStr を &str に読み替えようとすると、「0xff000000 から 8 バイトの MyStr 文字列を、 0x00000008 から 4278190080 バイトの str の文字列と見做す」という挙動になってしまうのである。
この操作は未定義動作であり、不正なメモリアクセスや予期せぬコンパイル結果を発生させるおそれがある。


&str と &MyStr のメモリレイアウトが一致していない場合、「&MyStr の値をあたかも &str の値であるかのように解釈する」のは不正である
コンパイラは、 #[repr(..)] の指定されていない型のメモリレイアウトの決定について裁量を持っており、またその後方互換性も担保されない。
すなわち、単純に struct MyStr(str); などのようにしただけではメモリレイアウトの互換性は保証されないし、もしある環境のあるバージョンのコンパイラでたまたま互換性があったとしても、他の環境や別のバージョンにおいて同様に互換性があるとは限らないのである。
以上より、 #[repr(transparent)] が必要な理由は「参照型のメモリレイアウトの互換性を保証することで、参照型の読み替えによるキャストを安全に実装可能にするため」であると説明できる。
所有権付きの型の定義
特筆すべきことはない。 書くだけである。
/// My custom owned string type.
#[derive(Default, Clone, PartialEq, Eq, PartialOrd, Ord, Hash)]
// Comparisons implemented for the type are consistent (at least it is intended to be so).
// See <https://github.com/rust-lang/rust-clippy/issues/2025>.
#[allow(clippy::derive_hash_xor_eq, clippy::derive_ord_xor_partial_ord)]
pub struct MyString(String);
/// Owned ASCII string type.
#[derive(Default, Clone, PartialEq, Eq, PartialOrd, Ord, Hash)]
// Comparisons implemented for the type are consistent (at least it is intended to be so).
// See <https://github.com/rust-lang/rust-clippy/issues/2025>.
#[allow(clippy::derive_hash_xor_eq, clippy::derive_ord_xor_partial_ord)]
pub struct AsciiString(String);
/// Owned ASCII string type.
#[derive(Default, Clone, PartialEq, Eq, PartialOrd, Ord, Hash)]
// Comparisons implemented for the type are consistent (at least it is intended to be so).
// See <https://github.com/rust-lang/rust-clippy/issues/2025>.
#[allow(clippy::derive_hash_xor_eq, clippy::derive_ord_xor_partial_ord)]
pub struct AsciiByteBuf(String);
敢えて指摘するなら、 #[repr(transparent)] が不要であること、 Default, Clone, Copy トレイトが derive 可能であることがスライス型の定義との違いである。
スライス型のメソッド定義
型の定義ができたら、次は基本的な型変換を実装しよう。 スライス型は参照の形でしか扱えないため、中身の値をフィールドに突っ込んでやれば値を作れる sized な型とは勝手が違う。
値の作成
追加の制約なしの型の場合
まずは追加の制約なしの型から考えよう。 先の節で説明したように、スライス型の変換は解釈の切り替えによって行う。
#[repr(transparent)]
pub struct MyStr(str);
impl MyStr {
#[inline]
#[must_use]
pub fn new(s: &str) -> &Self {
unsafe { &*(s as *const str as *const Self) }
}
#[inline]
#[must_use]
pub fn new_mut(s: &mut str) -> &mut Self {
unsafe { &mut *(s as *mut str as *mut Self) }
}
}
ここで unsafe は本質的に不可避であることに留意せよ。
また #[inline] と #[must_use] は任意だが、私は付けることにしている。
なぜなら関数は値の解釈の変更以外の実務を一切行わず、また副作用がないため利用しない解釈変更を行うことはナンセンスだからである。
(もっとも、このくらいであればわざわざ注釈を付けずとも普通に最適化で消されるが……)
これらの関数は、後に From トレイトや AsRef トレイトを実装する際に利用できる。
追加の制約付きの型の場合
エラー型
追加の制約があって値の変換が失敗しうる場合、多少の下準備が必要になる。 まずは検査を行う関数と、そこから返すエラー型を用意する。
/// Error for conversion from bytes to ASCII string.
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
pub struct AsciiError {
valid_up_to: usize,
invalid_byte: u8,
}
impl AsciiError {
pub fn valid_up_to(&self) -> usize {
self.valid_up_to
}
pub fn invalid_byte(&self) -> u8 {
self.invalid_byte
}
}
impl core::fmt::Display for AsciiError {
fn fmt(&self, f: &mut core::fmt::Formatter<'_>) -> core::fmt::Result {
write!(
f,
"invalid ASCII character {:#02x?} found at index {}",
self.invalid_byte, self.valid_up_to
)
}
}
impl std::error::Error for AsciiError {}
std::str::Utf8Error を参考にした。
内部の型のみから作る場合
エラー型ができたら、これを使って検査が書ける。
impl AsciiStr {
fn validate(s: &str) -> Result<(), AsciiError> {
match s.bytes().enumerate().find(|(_pos, byte)| !byte.is_ascii()) {
Some((pos, byte)) => Err(AsciiError {
valid_up_to: pos,
invalid_byte: byte,
}),
None => Ok(()),
}
}
}
この検査はちょっとしたパーサのようなものになるかもしれないが、大事なのはエラーかそうでないか、エラーならどのようなエラーか、それだけである。
よって戻り値の型は Result<(), Error> のようなものになる。
さて、検査ができるようになったら次は値の変換である。 とりあえず検査なしの単純な (必ずしも安全でない) 型変換から書こう。
impl AsciiStr {
/// Creates a new ASCII string slice from the given UTF-8 string slice.
///
/// # Safety
///
/// The given bytes should consists of only ASCII characters.
/// If this constraint is violated, undefined behavior results.
pub unsafe fn new_unchecked(s: &str) -> &Self {
&*(s as *const str as *const Self)
}
/// Creates a new mutable ASCII string slice from the given mutable UTF-8 string slice.
///
/// # Safety
///
/// The given bytes should consists of only ASCII characters.
/// If this constraint is violated, undefined behavior results.
pub unsafe fn new_unchecked_mut(s: &mut str) -> &mut Self {
&mut *(s as *mut str as *mut Self)
}
}
_unchecked を含む
Rust API guidelines では、unsafe な関数において、呼び出し側が守るべき不変条件のすべてを doc comment の Safety セクションで提示することを推奨している。 利用者が安全に関数を呼び出すために不可欠な情報のため、必ず doc comment で説明するべきである。
検査なしの変換が実装できたら、次は検査ありの安全な変換である。 戻り値の型に注意して実装する。
impl AsciiStr {
pub fn new(s: &str) -> Result<&Self, AsciiError> {
match Self::validate(s) {
Ok(_) => Ok(unsafe {
// SAFETY: This is safe because the string is successfully validated.
Self::new_unchecked(s)
}),
Err(e) => Err(e),
}
}
pub fn new_mut(s: &mut str) -> Result<&mut Self, AsciiError> {
match Self::validate(s) {
Ok(_) => Ok(unsafe {
// SAFETY: This is safe because the string is successfully validated.
Self::new_unchecked_mut(s)
}),
Err(e) => Err(e),
}
}
}
これで、効率的だが安全性の検査がスキップされるものと、検査が必ず強制される安全なものが実装できた。
これらの関数は、後に TryFrom トレイトを実装する際に利用できる。
内部の型と異なる型から作る場合
ASCII 文字列はバイト列として扱いたい場合も多いだろう。
そこで AsciiBytes では、内部的には UTF-8 の str 型で保持しつつ、値は &[u8] からも作れるようにしよう。
まず、検査では &str でなく &[u8] を受け取る。
&str はノーコストで &[u8] に変換できるから、これは &str から値を作りたいときにも使える。
#[repr(transparent)]
pub struct AsciiBytes(str);
impl AsciiBytes {
fn validate_bytes(s: &[u8]) -> Result<(), AsciiError> {
match s
.iter()
.copied()
.enumerate()
.find(|(_pos, byte)| !byte.is_ascii())
{
Some((pos, byte)) => Err(AsciiError {
valid_up_to: pos,
invalid_byte: byte,
}),
None => Ok(()),
}
}
}
続けて unsafe な値の作成。
一度 &[u8] を &str に変換してから、いつもの変換をかける。
ASCII 文字列は明らかに妥当な UTF-8 バイト列でもあるため、 core::str::from_utf8() を呼び出すことができる。
impl AsciiBytes {
/// Creates a new ASCII string slice from the given bytes.
///
/// # Safety
///
/// The given bytes should consists of only ASCII characters.
/// If this constraint is violated, undefined behavior results.
pub unsafe fn new_unchecked(bytes: &[u8]) -> &Self {
// SAFETY: This is safe because ASCII string is a valid UTF-8 sequence.
let s = core::str::from_utf8_unchecked(bytes);
&*(s as *const str as *const Self)
}
/// Creates a new mutable ASCII string slice from the given mutable bytes.
///
/// # Safety
///
/// The given bytes should consists of only ASCII characters.
/// If this constraint is violated, undefined behavior results.
pub unsafe fn new_unchecked_mut(bytes: &mut [u8]) -> &mut Self {
// SAFETY: This is safe because ASCII string is a valid UTF-8 sequence.
let s = core::str::from_utf8_unchecked_mut(bytes);
Self::from_mut_str_unchecked(s)
}
/// Creates a new mutable ASCII string slice from the given mutable bytes.
///
/// # Safety
///
/// The given bytes should consists of only ASCII characters.
/// If this constraint is violated, undefined behavior results.
unsafe fn from_mut_str_unchecked(s: &mut str) -> &mut Self {
&mut *(s as *mut str as *mut Self)
}
}
&[u8] を一度 &str に変換して、段階的に &AsciiBytes へと変換する。
AsciiBytes の内部の型は str であるから、横着して一気にキャストせず、 core::str::from_utf8_unchecked() 等で &[u8] を一度 &str に変換したのちそれを &AsciiBytes に変換する。
from_mut_str_unchecked() を別のメソッドとして分離したのは、あとで使うためである。
使う予定がないなら new_unchecked_mut() 内で全てを済ませてもよい。
あとは safe な値の作成。
今回は &[u8] と &str の両方を受け取れるよう、 AsRef<[u8]> を使うことにしよう。
impl AsciiBytes {
fn from_bytes(s: &[u8]) -> Result<&Self, AsciiError> {
match Self::validate_bytes(s) {
Ok(_) => Ok(unsafe {
// SAFETY: This is safe because the string is successfully validated.
Self::new_unchecked(s)
}),
Err(e) => Err(e),
}
}
#[inline]
pub fn new<T: ?Sized + AsRef<[u8]>>(s: &T) -> Result<&Self, AsciiError> {
Self::from_bytes(s.as_ref())
}
pub fn from_bytes_mut(s: &mut [u8]) -> Result<&mut Self, AsciiError> {
match Self::validate_bytes(s) {
Ok(_) => Ok(unsafe {
// SAFETY: This is safe because the string is successfully validated.
Self::new_unchecked_mut(s)
}),
Err(e) => Err(e),
}
}
#[inline]
pub fn new_mut<T: ?Sized + AsMut<[u8]>>(s: &mut T) -> Result<&mut Self, AsciiError> {
Self::from_bytes_mut(s.as_mut())
}
#[inline]
pub fn from_mut_str(s: &mut str) -> Result<&mut Self, AsciiError> {
// SAFETY: `AsciiBytes` guarantees that the string is an ASCII string,
// and ASCII string is valid UTF-8 sequence.
let bytes = unsafe { s.as_bytes_mut() };
Self::from_bytes_mut(bytes)
}
}
敢えて new() で完結させず .as_ref() だけ済ませて from_bytes() に処理を移譲しているのは、バイナリサイズやコンパイル時間増大の回避のためである。
もしこれらを new() 内で済ませてしまうと、 Self::validate_bytes() を呼び出すような new 関数の実体が T 型の種類分だけ作られ、それぞれについて最適化やバイナリ生成が行われることになるだろう。
このようなコード重複は無駄であるため、本命の処理を使う前に型を合流させてしまうのである。
このような手動での事前の単一化 (monomorphization) は コンパイル時間の短縮と生成されるバイナリの縮小に貢献することが知られている。
型パラメータ T には [u8] 等のサイズ不定な DST が来ることを想定しているため、 T: ?Sized でサイズ不定でも構わないと明示する必要がある。
from_mut_str() を new_mut() と別で用意しているのは、 str が AsMut<str> を実装していないからである[8]。
受け付ける型と内部の型が一致しない場合、こういう面倒が増えるので多少の覚悟が必要である。
元の型へのキャスト
元の型へのキャストは基本的に失敗しないため、 safe かつ単純に書ける。
impl MyStr {
#[inline]
#[must_use]
pub fn as_str(&self) -> &str {
&self.0
}
#[inline]
#[must_use]
pub fn as_mut_str(&mut self) -> &mut str {
&mut self.0
}
}
ここで注意すべきなのは、元の型に追加の制約を加えた型の場合、元の型への可変参照を safe に返してはいけない ということである。
impl AsciiStr {
#[inline]
#[must_use]
pub fn as_str(&self) -> &str {
&self.0
}
/// Converts a mutable ASCII string slice into a mutable UTF-8 string slice.
///
/// # Safety
///
/// The caller must ensure that the string is an ASCII string when the borrow ends.
///
/// Use of an `AsciiStr` which contains non-ASCII characters is undefined behavior.
#[inline]
#[must_use]
pub unsafe fn as_mut_str(&mut self) -> &mut str {
&mut self.0
}
}
as_mut_str が unsafe であることに注目AsciiStr は値の作成や編集の際に適切な検査を行うことで str への追加の制約を遵守する必要がある。
しかし、内部の &mut str を直接取り出してユーザが編集を行うと、 AsciiStr 型がその内容を検査することはできなくなる[9]。
そのため、編集が完了して値へのコントロールが AsciiStr へと戻ってきた時点で内容が妥当なものであることを条件として、 unsafe な関数として内部データへのアクセスを提供するのが一般的である。
たとえば str は unsafe な str::as_bytes_mut() によって内部の &mut [u8] へのアクセスを提供している。
これらの関数は、後に AsRef トレイト、 Deref トレイト、 From トレイト等を実装する際に利用できる。
AsciiBytes 型の実装例は AsciiStr のものと同様になるので省略する。
所有権付きの型のメソッド定義
追加の制約なしの場合
やるだけ。 やろう。
pub struct MyString(String);
impl MyString {
#[inline]
#[must_use]
pub fn new(s: String) -> Self {
Self(s)
}
}
ついでに、のちのちトレイト定義で使うための便利メソッドも用意しておこう。
impl MyString {
#[inline]
#[must_use]
pub fn as_my_str(&self) -> &MyStr {
MyStr::new(self.0.as_str())
}
#[inline]
#[must_use]
pub fn as_my_str_mut(&mut self) -> &mut MyStr {
MyStr::new_mut(self.0.as_mut_str())
}
}
もしユーザに公開するつもりがなければ、 pub でなくプライベートなメソッドにしておこう。
普通は (String::as_str() がそうであるように) 公開してしまうものだと思うが、たとえば AsRef や Deref 経由で変換を提供することもできるので、公開が必須というわけでもない。
追加の制約付きの場合
制約がある場合、エラー型については多少の工夫の余地がある。
内部の型からしか作成を許さない場合
内部の型からしか作成を許さない単純なインターフェースにする場合、まずエラー型がこのようになる。
#[derive(Debug, Clone)]
pub struct FromStringError {
source: String,
error: AsciiError,
}
impl FromStringError {
#[inline]
#[must_use]
pub fn as_str(&self) -> &str {
&self.source
}
#[inline]
#[must_use]
pub fn into_string(self) -> String {
self.source
}
#[inline]
#[must_use]
pub fn ascii_error(&self) -> AsciiError {
self.error
}
}
impl core::fmt::Display for FromStringError {
fn fmt(&self, f: &mut core::fmt::Formatter<'_>) -> core::fmt::Result {
self.error.fmt(f)
}
}
impl std::error::Error for FromStringError {}
std::string::FromUtf8Error 型が参考になる。
AsciiString の作成に失敗した場合に、元となる値の所有権を消費せずエラーに含めて返す (この例では into_string() で取り出せるようにする) というのがポイントである。
これによって、「もし AsciiString でなかったらアルファベットへの変換をかけて、改めて作成を試みる」のようなことが追加のアロケーションなしで可能になる。
このエラー型を使って変換を書く。
pub struct AsciiString(String);
impl AsciiString {
/// Creates a new `AsciiString` from the given string.
///
/// # Safety
///
/// The given string must be an ASCII string.
/// If this constraint is violated, undefined behavior results.
pub unsafe fn new_unchecked(s: String) -> Self {
Self(s)
}
pub fn new(s: String) -> Result<Self, FromStringError> {
match AsciiStr::validate(&s) {
Ok(_) => Ok(unsafe {
// SAFETY: This is safe because the string is successfully validated.
Self::new_unchecked(s)
}),
Err(e) => Err(FromStringError {
source: s,
error: e,
}),
}
}
}
面白さの欠片もないが、 new_unchecked(s: &String) を unsafe にする のは大変重要である。
Self(s) 自体は unsafe なしで書ける処理であるが、ここで渡された s を無条件に受け入れてよいわけではないことに留意しなければならない。
もし s が ASCII 文字列でなかった場合、不正な AsciiString を作り未定義動作を誘発することになりかねないため、検査なしでそのような危険な処理を行うこの関数は unsafe なのである。
他にポイントがあるとすれば、 AsciiStr::validate(&s) のように検証をスライス型の方に移譲しているのと、エラー値の作成で新しく作ったエラー型の方を作っているくらいだろうか。
内部の型以外からの作成も認める場合
複数の型の値からの作成を認める場合、元となる値をエラーに含めて返すためには多相なエラー型が必要となる。
名前も FromStringError では string 以外から作ろうとしたとき微妙な感じなので、 CreationError のような一般的な名前にしよう。
#[derive(Debug, Clone)]
pub struct CreationError<T> {
source: T,
error: AsciiError,
}
impl<T> CreationError<T> {
#[inline]
#[must_use]
pub fn source(&self) -> &T {
&self.source
}
#[inline]
#[must_use]
pub fn into_source(self) -> T {
self.source
}
#[inline]
#[must_use]
pub fn ascii_error(&self) -> AsciiError {
self.error
}
}
impl<T> core::fmt::Display for CreationError<T> {
fn fmt(&self, f: &mut core::fmt::Formatter<'_>) -> core::fmt::Result {
self.error.fmt(f)
}
}
impl<T: core::fmt::Debug> std::error::Error for CreationError<T> {}
FromStringError とほぼ同じである。
値の作成では、 AsciiBytes::new_unchecked() と同様、 Vec<u8> を一度 String を経由して AsciiByteBuf に変換する。
pub struct AsciiByteBuf(String);
impl AsciiByteBuf {
/// Creates a new `AsciiByteBuf` from the given string.
///
/// # Safety
///
/// The given string must be an ASCII string.
/// If this constraint is violated, undefined behavior results.
pub unsafe fn from_string_unchecked(s: String) -> Self {
Self(s)
}
/// Creates a new `AsciiByteBuf` from the given bytes.
///
/// # Safety
///
/// The given bytes must be an ASCII string.
/// If this constraint is violated, undefined behavior results.
pub unsafe fn from_bytes_unchecked(bytes: Vec<u8>) -> Self {
// SAFETY: `bytes` must be an ASCII string, and an ASCII string is
// also a valid UTF-8 string.
let s = String::from_utf8_unchecked(bytes);
Self(s)
}
pub fn new<T: Into<Vec<u8>> + AsRef<[u8]>>(s: T) -> Result<Self, CreationError<T>> {
match AsciiBytes::validate_bytes(s.as_ref()) {
Ok(_) => Ok(unsafe {
// SAFETY: This is safe because the string is successfully validated.
Self::from_bytes_unchecked(s.into())
}),
Err(e) => Err(CreationError {
source: s,
error: e,
}),
}
}
}
new() の引数となる型には、最終的に Vec<u8> にするための Into<Vec<u8>> と、検査で必要な &[u8] を取り出すための AsRef<[u8]> の trait bound が必要である。
便利メソッド
のちのちトレイト実装で使うため、やはり便利メソッドも実装しておく。
impl AsciiString {
#[inline]
#[must_use]
pub fn as_ascii_str(&self) -> &AsciiStr {
unsafe {
// SAFETY: `self` is an ASCII string.
AsciiStr::new_unchecked(self.0.as_str())
}
}
#[inline]
#[must_use]
pub fn as_ascii_str_mut(&mut self) -> &mut AsciiStr {
unsafe {
// SAFETY: `self` is an ASCII string.
AsciiStr::new_unchecked_mut(self.0.as_mut_str())
}
}
}
いきなり AsciiString を AsciiStr にするのではなく、 String と &str を経由する。
self.0 で String を取り出し、 .as_str() で &str にして、最後に AsciiStr::new_unchecked で &AsciiStrを得る。
ほとんど同じになるが、一応 AsciiBytes の実装も載せておこう。
impl AsciiByteBuf {
#[inline]
#[must_use]
pub fn as_ascii_bytes(&self) -> &AsciiBytes {
unsafe {
// SAFETY: `self` is an ASCII string.
AsciiBytes::new_unchecked(self.0.as_str().as_bytes())
}
}
#[inline]
#[must_use]
pub fn as_ascii_bytes_mut(&mut self) -> &mut AsciiBytes {
unsafe {
// SAFETY: `self` is an ASCII string.
AsciiBytes::from_mut_str_unchecked(self.0.as_mut_str())
}
}
}
AsciiStr での例と違うのは、 AsciiStr::new_unchecked_mut の代わりに AsciiBytes::from_mut_str_unchecked() を使っている点だけである。
このような「独自型と別の型の間で直接変換が難しい場合、内部の型を経由して多段階で変換を行う」という工夫は、以後のトレイト実装でも必要になる場面がある。
トレイト実装
From, TryFrom
説明するまでもないが、値の作成や変換に用いるトレイトである。
追加の制約なしでの値の作成
まず手始めに、 new() 相当のものから実装していこう。
impl<'a> From<&'a str> for &'a MyStr {
#[inline]
fn from(s: &'a str) -> Self {
MyStr::new(s)
}
}
impl<'a> From<&'a mut str> for &'a mut MyStr {
#[inline]
fn from(s: &'a mut str) -> Self {
MyStr::new_mut(s)
}
}
impl From<String> for MyString {
#[inline]
fn from(s: String) -> Self {
Self::new(s)
}
}
impl From<&str> for MyString {
#[inline]
fn from(s: &str) -> Self {
Self::new(s.to_owned())
}
}
'a が多いが、残念ながら明示する必要があるので諦めて書こう。
それから、 &str など独自スライス型の内部の型からの作成もあとで使いたくなることがあるため、実装しておくのがよい。
&mut str などからの変換も実装しておくと便利かもしれないが、そこはお好みである。
ちなみに From<&mut str> for String は割と最近 (Rust 1.44.0) になって実装が追加された。
追加の制約付きでの値の作成
impl<'a> TryFrom<&'a str> for &'a AsciiStr {
type Error = AsciiError;
#[inline]
fn try_from(s: &'a str) -> Result<Self, Self::Error> {
AsciiStr::new(s)
}
}
impl<'a> TryFrom<&'a mut str> for &'a mut AsciiStr {
type Error = AsciiError;
#[inline]
fn try_from(s: &'a mut str) -> Result<Self, Self::Error> {
AsciiStr::new_mut(s)
}
}
またしても 'a が多いが、残念ながら明示する必要があるので諦めて書こう。
AsciiBytes 用の実装はほぼ同じなので省略。
impl TryFrom<String> for AsciiString {
type Error = FromStringError;
#[inline]
fn try_from(s: String) -> Result<Self, Self::Error> {
Self::new(s)
}
}
impl TryFrom<&str> for AsciiString {
type Error = AsciiError;
fn try_from(s: &str) -> Result<Self, Self::Error> {
AsciiStr::new(s).map(ToOwned::to_owned)
}
}
String のみを受け付ける版の実装型パラメータがない場合、かなり単純。 特に言うべきことはない。
impl<T: Into<Vec<u8>> + AsRef<[u8]>> TryFrom<T> for AsciiString {
type Error = CreationError<T>;
#[inline]
fn try_from(s: T) -> Result<Self, Self::Error> {
Self::new(s)
}
}
error[E0119]: conflicting implementations of trait `std::convert::TryFrom<_>` for type `ascii_bytes::owned::AsciiByteBuf`:
--> src/ascii_bytes.rs:241:5
|
241 | impl<T: Into<Vec<u8>> + AsRef<[u8]>> TryFrom<T> for AsciiByteBuf {
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: conflicting implementation in crate `core`:
- impl<T, U> std::convert::TryFrom<U> for T
where U: std::convert::Into<T>;
error: aborting due to previous error
For more information about this error, try `rustc --explain E0119`.
多相の場合、残念ながら TryFrom は思ったほど一般的にできない。
これは、第三者ユーザがたとえば Foo という型を定義して Into<AsciiString> for Foo, Into<Vec<u8>> for Foo, AsRef<[u8]> for Foo の3つのトレイト実装を用意してしまったとき、第三者ユーザが実装した Into<AsciiString> for Foo とあなたが実装した TryFrom<T> for AsciiString が競合すると言っているのである (TryFrom は Into が実装されている型の組に対して自動的に実装される。ちょうど Into と From と同様の関係である)。
根本的には「知らないところで第三者が定義するかもしれない型に対して余計なことをしすぎるな」という話なので、諦めて既知のめぼしい型に対して手作業で実装していこう。
impl TryFrom<String> for AsciiByteBuf {
type Error = CreationError<String>;
#[inline]
fn try_from(s: String) -> Result<Self, Self::Error> {
Self::new(s)
}
}
impl TryFrom<Vec<u8>> for AsciiByteBuf {
type Error = CreationError<Vec<u8>>;
#[inline]
fn try_from(s: Vec<u8>) -> Result<Self, Self::Error> {
Self::new(s)
}
}
impl<'a> TryFrom<&'a str> for AsciiByteBuf {
type Error = CreationError<&'a str>;
fn try_from(s: &'a str) -> Result<Self, Self::Error> {
match AsciiBytes::new(s) {
Ok(v) => Ok(v.to_owned()),
Err(e) => Err(CreationError {
source: s,
error: e,
}),
}
}
}
impl<'a> TryFrom<&'a [u8]> for AsciiByteBuf {
type Error = CreationError<&'a [u8]>;
fn try_from(s: &'a [u8]) -> Result<Self, Self::Error> {
match AsciiBytes::new(s) {
Ok(v) => Ok(v.to_owned()),
Err(e) => Err(CreationError {
source: s,
error: e,
}),
}
}
}
ここで注意すべきなのは、検査の前にアロケーションを発生させるべきでないという点である。
&str から String を作った後にエラーが発覚した場合、 String 作成のためのメモリアロケーションは全くの無駄となってしまう。
これを避けるべく、例では検査と同時に &AsciiBytes を先に作り、そこから後で実装するToOwned トレイトを利用して AsciiByteBuf を作成した。
もちろん &AsciiBytes を経由しない方法もあり、たとえば以下のように実装することもできる。
impl<'a> TryFrom<&'a str> for AsciiByteBuf {
type Error = CreationError<&'a str>;
fn try_from(s: &'a str) -> Result<Self, Self::Error> {
match AsciiBytes::validate_bytes(s.as_bytes()) {
Ok(_) => Ok(unsafe {
// SAFETY: `s` is already validated.
Self::from_string_unchecked(s.to_owned())
}),
Err(e) => Err(CreationError {
source: s,
error: e,
}),
}
}
}
impl<'a> TryFrom<&'a [u8]> for AsciiByteBuf {
type Error = CreationError<&'a [u8]>;
fn try_from(s: &'a [u8]) -> Result<Self, Self::Error> {
match AsciiBytes::validate_bytes(s) {
Ok(_) => Ok(unsafe {
// SAFETY: `s` is already validated.
Self::from_bytes_unchecked(s.to_owned())
}),
Err(e) => Err(CreationError {
source: s,
error: e,
}),
}
}
}
&AsciiBytes を経由しないが unsafe なコードになる。
個人的には独自スライス型 (ここでは AsciiBytes) を経由する方がシンプルで良いと思うが、まあ好みの問題だろう。
内側の型を取り出す
ここまでで外側の (新しく用意した) 型の値を作成する実装ができたので、次は逆向き、内側の値を取り出す実装である。 これは失敗しないので簡単だ。
impl<'a> From<&'a MyStr> for &'a str {
#[inline]
fn from(s: &'a MyStr) -> Self {
s.as_str()
}
}
impl<'a> From<&'a mut MyStr> for &'a mut str {
#[inline]
fn from(s: &'a mut MyStr) -> Self {
s.as_mut_str()
}
}
impl From<MyString> for String {
#[inline]
fn from(s: MyString) -> Self {
s.0
}
}
impl<'a> From<&'a AsciiStr> for &'a str {
#[inline]
fn from(s: &'a AsciiStr) -> Self {
s.as_str()
}
}
impl From<AsciiString> for String {
#[inline]
fn from(s: AsciiString) -> Self {
s.0
}
}
コードを載せる価値があるか疑問さえ湧いてくるつまらなさである。
AsciiBytes と AsciiByteBuf 用の実装も AsciiStr / AsciiString と同様なので省略する。
追加の制約付きの型では、 From<&'a mut AsciiStr> for &'a mut str のような中身を露出する実装がないことに注意。
まあうっかり書きそうになっても as_mut_str() は unsafe な関数なので、書いている途中でおかしいと気付くはずである。
スマートポインタとの変換
これが絶妙に非自明なので詳しく解説する。
スライスからスマートポインタへの変換
先にスライスからスマートポインタへの変換を考える。
impl From<&MyStr> for Box<MyStr> {
fn from(s: &MyStr) -> Self {
// Create the boxed inner slice.
let inner_box: Box<str> = Box::from(s.as_str());
// Take the allocated memory out of the box, without releasing.
let inner_boxed_ptr: *mut str = Box::into_raw(inner_box);
unsafe {
// SAFETY: The string is valid as `MyStr`.
// SAFETY: Memory layouts for `str` and `MyStr` are compatible,
// and `inner_boxed_ptr` is allocated by `Box::<str>::from()`.
Box::from_raw(inner_boxed_ptr as *mut MyStr)
}
}
}
Box<MyStr> の作成Box<MyStr> を直接作るのでなく、 &MyStr → &str → Box<str> → *mut str → *mut MyStr → Box<MyStr> というように、作り方が std より提供されている Box<str> を起点として、 mut 生ポインタを経由して MyStr へ型変換することで値を作る。
// Create the boxed inner slice.
let inner_box: Box<str> = Box::from(s.as_str());
s.as_str() で &MyStr → &str、 Box::from() で &str → Box<str>。
まずは Box<str> を作ることを目標にする。そのため、 &MyStr から中身の &str を取り出し、ここから Box::from() で boxed string を作成する。
Box::from() 内でメモリアロケーションが発生し、 &str が確保されたメモリ領域にコピーされる。
// Take the allocated memory out of the box, without releasing.
let inner_boxed_ptr: *mut str = Box::into_raw(inner_box);
Box::into_raw() で Box<str> → *mut strBox::into_raw() は、確保されたメモリ領域をそのままに Box 自体を解体する。
Box から別の型の Box へと安全に直接変換する方法がないため、一度生ポインタを経由してキャスト (型の読み替え) をしてやる必要があるのである。
もちろん生ポインタは所有権管理が自動ではないため、後で Box::from_raw() によって再び Box へと再構築してやらないとメモリリークとなる。
unsafe {
// SAFETY: The string is valid as `MyStr`.
// SAFETY: Memory layouts for `str` and `MyStr` are compatible,
// and `inner_boxed_ptr` is allocated by `Box::<str>::from()`.
Box::from_raw(inner_boxed_ptr as *mut MyStr)
}
inner_boxed_ptr as *mut MyStr で *mut str → *mut MyStr、 Box::from_raw() で *mut MyStr → Box<MyStr>。
ここでは2つの不変条件 (invariant) が要求されていることに注意せよ。
ひとつは inner_boxed_ptr: *mut str を *mut MyStr にキャストするための、「ポインタで指されたデータが MyStr として妥当である」という条件。
MyStr の例では追加の制約はないが、もし AsciiStr のように追加の制約があっても問題ない。
そもそも元になったデータが、引数として渡された s: &MyStr や s: &AsciiStr などの自分自身そのものの型であり、受け取って以降に値の加工は行っていないから、この不変条件は自明に満たされる。
もうひとつの不変条件は Box::from_raw() で生ポインタから Box を安全に作るための条件である。
For non-zero-sized values, a
Boxwill use theGlobalallocator for its allocation. It is valid to convert both ways between aBoxand a raw pointer allocated with theGlobalallocator, given that theLayoutused with the allocator is correct for the type.
端的に言えば、 Box<T> が内部的にメモリアロケーションに用いるのと同じメモリレイアウトで確保された領域であれば、 Box::<T>::from_raw() に渡しても安全であるということである。
MyStr の例については、 #[repr(transparent)] によってメモリレイアウトが str と互換になることが保証されているため、 Box<str> が確保する領域のメモリレイアウトと Box<MyStr> が確保する領域のそれも互換である。
すなわち、 Box::<str>::from() が確保するメモリ領域は Box::<MyStr>::from() が確保するであろうメモリ領域と互換なレイアウトを持つはずであるため、そのどちらも安全に Box::<MyStr>::from_raw() に渡すことができるというわけである。
// `fn from` in `impl From<&CStr> for Box<CStr>` current implementation relies
// on `CStr` being layout-compatible with `[u8]`.
// When attribute privacy is implemented, `CStr` should be annotated as `#[repr(transparent)]`.
std::ffi::CStr の定義についてのコメント (抜粋)。
さて、 Box への変換はこれで実装できた。
同じようなスマートポインタであるところの std::rc::Rc と std::sync::Arc も、ほとんど同じようなものである。
use std::rc::Rc;
use std::sync::Arc;
impl From<&MyStr> for Rc<MyStr> {
fn from(s: &MyStr) -> Self {
// Create the shared inner slice.
let inner_box: Rc<str> = Rc::from(s.as_str());
// Take the allocated memory out of the Rc, without releasing.
let inner_boxed_ptr: *const str = Rc::into_raw(inner_box);
unsafe {
// SAFETY: The string is valid as `MyStr`.
// SAFETY: Memory layouts for `str` and `MyStr` are compatible,
// and `inner_boxed_ptr` is allocated by `Rc::<str>::from()`.
Rc::from_raw(inner_boxed_ptr as *const MyStr)
}
}
}
impl From<&MyStr> for Arc<MyStr> {
fn from(s: &MyStr) -> Self {
// Create the shared inner slice.
let inner_box: Arc<str> = Arc::from(s.as_str());
// Take the allocated memory out of the Arc, without releasing.
let inner_boxed_ptr: *const str = Arc::into_raw(inner_box);
unsafe {
// SAFETY: The string is valid as `MyStr`.
// SAFETY: Memory layouts for `str` and `MyStr` are compatible,
// and `inner_boxed_ptr` is allocated by `Arc::<str>::from()`.
Arc::from_raw(inner_boxed_ptr as *const MyStr)
}
}
}
Rc<MyStr> と Arc<MyStr> の作成Rc と Arc は型名 (コメント内のものも含む) 以外全く同じコードである。
何度も書きそうであれば、マクロ化してしまうのも手だろう。
Box との違いは、 into_raw() が返す生ポインタの mutability である。
Box では確保されたメモリの唯一の所有者が box 自身なので、 mutable な生ポインタを返せる。
一方、 Rc や Arc では自分以外にも同じメモリ領域を参照しているものがあるかもしれないため所有権を奪うことはできず、参照者が唯一である保証ができないため const な生ポインタを返すしかない。
追加の制約付きの型 (例では AsciiStr と AsciiBytes) についても全く同様のコードになるので、実装例は省略する。
所有権付きの型からスマートポインタへの変換
所有権付きの型からの変換も、スライスからの変換と同様に既存の String や Vec<T> 等の実装を経由して実装する。
impl From<MyString> for Box<MyStr> {
fn from(s: MyString) -> Self {
// Create the boxed inner slice.
let inner_box: Box<str> = Box::from(s.0);
// Take the allocated memory out of the box, without releasing.
let inner_boxed_ptr: *mut str = Box::into_raw(inner_box);
unsafe {
// SAFETY: The string is valid as `MyStr`.
// SAFETY: Memory layouts for `str` and `MyStr` are compatible,
// and `inner_boxed_ptr` is allocated by `Box::<str>::from()`.
Box::from_raw(inner_boxed_ptr as *mut MyStr)
}
}
}
MyString からの Box<MyStr> の作成
やっていることは本質的にはスライス型からの変化と同じで、 Box::from(s.as_str()) で &str から Box を作っていたところを、 Box::from(s.0) で String から Box を作るよう変更しただけである。
use std::rc::Rc;
use std::sync::Arc;
impl From<MyString> for Rc<MyStr> {
fn from(s: MyString) -> Self {
// Create the shared inner slice.
let inner_box: Rc<str> = Rc::from(s.0);
// Take the allocated memory out of the Rc, without releasing.
let inner_boxed_ptr: *const str = Rc::into_raw(inner_box);
unsafe {
// SAFETY: The string is valid as `MyStr`.
// SAFETY: Memory layouts for `str` and `MyStr` are compatible,
// and `inner_boxed_ptr` is allocated by `Rc::<str>::from()`.
Rc::from_raw(inner_boxed_ptr as *const MyStr)
}
}
}
impl From<MyString> for Arc<MyStr> {
fn from(s: MyString) -> Self {
// Create the shared inner slice.
let inner_box: Arc<str> = Arc::from(s.0);
// Take the allocated memory out of the Arc, without releasing.
let inner_boxed_ptr: *const str = Arc::into_raw(inner_box);
unsafe {
// SAFETY: The string is valid as `MyStr`.
// SAFETY: Memory layouts for `str` and `MyStr` are compatible,
// and `inner_boxed_ptr` is allocated by `Arc::<str>::from()`.
Arc::from_raw(inner_boxed_ptr as *const MyStr)
}
}
}
MyString からの Rc<MyStr> と Arc<MyStr> の作成Rc と Arc についても同様で、特に語るべきことはない。
また AsciiString や AsciiByteBuf のような追加の制限付きの型でも同様の実装になるため、これも例は省略する。
Cowとの変換
impl<'a> From<&'a MyStr> for Cow<'a, MyStr> {
#[inline]
fn from(s: &'a MyStr) -> Self {
Cow::Borrowed(s)
}
}
impl From<MyString> for Cow<'_, MyStr> {
#[inline]
fn from(s: MyString) -> Self {
Cow::Owned(s)
}
}
やるだけ。
追加の制約があってもなくても同様の実装になるので AsciiStr と AsciiBytes の例は省略。
FromStr
FromStr トレイトが実装されていると、 .parse() が利用可能になる。
変換するだけなら TryFrom<&str> か From<&str> があれば十分なのだが、一応有用そうであれば実装しておくと良い。
impl core::str::FromStr for MyString {
type Err = core::convert::Infallible;
#[inline]
fn from_str(s: &str) -> Result<Self, Self::Err> {
Ok(s.into())
}
}
失敗しない変換であれば From で既に実装済のはずなので、そちらに丸投げする。
エラー型としては core::convert::Infallible を使う。
これは実行時に値を持てない型で、最適化に強力に貢献するはずである。
impl core::str::FromStr for AsciiString {
type Err = AsciiError;
#[inline]
fn from_str(s: &str) -> Result<Self, Self::Err> {
TryFrom::try_from(s)
}
}
失敗しうる変換であれば TryFrom で既に実装済のはずなので、そちらに丸投げする。
Deref, DerefMut
Deref と DerefMut はある型を透過的に別の型への参照として振る舞わせるもので、非常に便利である一方、 strong typedef の「内部的には同じ型を別個のものとして区別させる」という目的と反するものでもある。
標準ライブラリのドキュメントでは、これらのトレイトはスマートポインタのみに実装すべきであると強調されている。
Implementing
Dereffor smart pointers makes accessing the data behind them convenient, which is why they implementDeref. On the other hand, the rules regardingDerefandDerefMutwere designed specifically to accommodate smart pointers. Because of this,Derefshould only be implemented for smart pointers to avoid confusion.
たとえば str は内部的には [u8] であるが、 Deref<Target=[u8]> for str は実装されていない。
このような「透過的に同一視されてほしいわけではない型」は AsRef<[u8]> だったり .as_bytes() で明示的な変換を行うべしということである。
一方で、 &String が透過的に &str として扱えてほしいとか Vec<u8> を透過的に &[u8] として扱いたいとかは全くもって正当な要求である。
実際、標準ライブラリでも Deref<Target=str> for String とか Deref<Target=[u8]> for Vec<u8> などの実装がされている。
よって、所有権付きの独自型から所有権なしのスライス型への Deref による変換は一般的に実装すべきである。
impl core::ops::Deref for MyString {
type Target = MyStr;
#[inline]
fn deref(&self) -> &Self::Target {
self.as_my_str()
}
}
impl core::ops::DerefMut for MyString {
#[inline]
fn deref_mut(&mut self) -> &mut Self::Target {
self.as_my_str_mut()
}
}
追加の制約の有無に関係なく同じような実装になるため、 AsciiString と AsciiByteBuf への実装例は省略する。
一応例としてコードは載せるが、特に所有権のないスライス型に本当に Deref を実装すべきかは熟慮すべきである。
困ったら実装せずにおくのがよい。
後から std や core のトレイトを実装しても breaking change にはならないはずである。
// Do you really want this?
impl core::ops::Deref for MyStr {
type Target = str;
#[inline]
fn deref(&self) -> &Self::Target {
&self.0
}
}
// Do you really REALLY want this?
impl core::ops::DerefMut for MyStr {
#[inline]
fn deref_mut(&mut self) -> &mut Self::Target {
&mut self.0
}
}
Deref と DerefMut の実装
再三繰り返すが、追加の制約がある型の場合、くれぐれも内側の型 (MyStr の例であれば str) への mutable 参照を safe に露出させてはいけない。
たとえば AsciiStr から DerefMut 経由で &mut str を露出させるのは厳禁である。
例のごとく、 AsciiStr と AsciiBytes への実装例は省略する。
AsRef, AsMut
これらのトレイトの必要性は用途にもよるため、場合によっては AsRef や AsMut の実装は不要かもしれないが、とりあえず実装例を提示する。
独自スライス型自体への変換
これは自分で実装していると意外に忘れがちだが、 AsRef<T> for T のような汎用的な実装は存在しない。
つまり、 T: AsRef<MySlice> のような trait bound を利用する可能性のある型には、自分で impl AsRef<MySlice> for MySlice のような実装を用意してやる必要がある。
impl AsRef<MyStr> for MyStr {
#[inline]
fn as_ref(&self) -> &MyStr {
self
}
}
impl AsMut<MyStr> for MyStr {
#[inline]
fn as_mut(&mut self) -> &mut MyStr {
self
}
}
impl AsRef<MyStr> for MyString {
#[inline]
fn as_ref(&self) -> &MyStr {
self.as_my_str()
}
}
impl AsMut<MyStr> for MyString {
#[inline]
fn as_mut(&mut self) -> &mut MyStr {
self.as_my_str_mut()
}
}
追加の制約の有無に関係なく実装は同様になるため、 AsciiStr と AsciiBytes の例は省略する。
元のスライス型への変換
追加の制約なしの型については何も考えず実装できる。
が、 Box に対する AsRef の実装をしておくと便利かもしれない。
impl AsRef<str> for MyStr {
#[inline]
fn as_ref(&self) -> &str {
self.as_str()
}
}
impl AsMut<str> for MyStr {
#[inline]
fn as_mut(&mut self) -> &mut str {
self.as_mut_str()
}
}
impl AsRef<str> for Box<MyStr> {
#[inline]
fn as_ref(&self) -> &str {
self.as_str()
}
}
impl AsRef<str> for MyString {
#[inline]
fn as_ref(&self) -> &str {
self.as_str()
}
}
impl AsMut<str> for MyString {
#[inline]
fn as_mut(&mut self) -> &mut str {
self.as_mut_str()
}
}
impl AsMut<str> for Box<MyStr> {
#[inline]
fn as_mut(&mut self) -> &mut str {
self.as_mut_str()
}
}
AsMut を実装してもよい。しなくともよい。メソッド実装の節でも指摘したように、 追加の制約のある型では元の型への mutable な参照を safe に返してはいけない。
つまり、そのような場合には AsMut を実装してはいけない。
impl AsRef<str> for AsciiStr {
#[inline]
fn as_ref(&self) -> &str {
self.as_str()
}
}
impl AsRef<str> for AsciiString {
#[inline]
fn as_ref(&self) -> &str {
self.as_str()
}
}
AsMut で内部の型を返してはいけないAsRef<str> for Box<MyStr> は稀に欲しいことがある。
この実装がなくとも v: Box<MyStr> から v.as_str() によって &strを得ることはできるが、 fn foo<T: AsRef<str>>(v: &T) のような関数に f(&v) と渡すことができない。
AsciiBytes については AsciiStr の場合と同様なので省略する。
その他の型への変換
元の型と自分自身への変換以外のスライス型への変換を実装しても良い (もちろん安全であればの話だが)。
たとえば str は AsRef<[u8]>, AsRef<std::ffi::OsStr>, AsRef<std::path::Path> 等のトレイト実装を持っている。
impl AsRef<[u8]> for MyStr {
#[inline]
fn as_ref(&self) -> &[u8] {
self.as_str().as_bytes()
}
}
impl AsRef<[u8]> for MyString {
#[inline]
fn as_ref(&self) -> &[u8] {
self.as_str().as_bytes()
}
}
AsRef<[u8]> を実装した例
どのような変換を実装するかは用途次第であり、 AsRef<[u8]> の実装例は MyStr と同様になるため、 AsciiStr と AsciiBytes でのコード例は省略する。
くれぐれも制約が緩くなるような変換で mutable な参照を返さないこと。
Debug, Display
一番ありがちなのは、 strong typedef によって表示が変化しないでほしいという場合であろう。
use core::fmt;
impl fmt::Debug for MyStr {
#[inline]
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
self.0.fmt(f)
}
}
impl fmt::Display for MyStr {
#[inline]
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
self.0.fmt(f)
}
}
impl fmt::Debug for MyString {
#[inline]
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
self.0.fmt(f)
}
}
impl fmt::Display for MyString {
#[inline]
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
self.0.fmt(f)
}
}
str と String) に処理を移譲した
この例では、内側の型 (MyStr の場合は str) の Debug と Display 実装をそのまま流用している。
何かしらの整形をして表示したくば、そのように実装すべきである。
上の例では両方で内側の型のトレイト実装へと丸投げしたが、もし独自スライス型で独自に整形を行うなら、所有権付きの型の実装は内部の型でなくスライス型の方へ丸投げした方が良い。
use core::fmt;
impl fmt::Debug for MyString {
#[inline]
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
self.as_my_str().fmt(f)
}
}
impl fmt::Display for MyString {
#[inline]
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
self.as_my_str().fmt(f)
}
}
self.0 ではなく self.as_my_str() で取得した独自スライス型の値へ整形を丸投げする手もある
追加の制約の有無は関係ないので、 AsciiStr や AsciiBytes などの実装例は省略。
ここでは一般的な Debug と Display だけを挙げたが、他の core::fmt の整形用トレイトで実装したいものがあれば好きに実装することができる。
Borrow, BorrowMut, ToOwned
これらはスライス型を独自に定義するうえで特に使い勝手に影響するトレイトである。
具体的には、 .to_owned() が使えるようになる[10]のと、 std::borrow::Cow が使えるようになる。
impl core::borrow::Borrow<MyStr> for MyString {
#[inline]
fn borrow(&self) -> &MyStr {
self.as_my_str()
}
}
impl core::borrow::BorrowMut<MyStr> for MyString {
#[inline]
fn borrow_mut(&mut self) -> &mut MyStr {
self.as_my_str_mut()
}
}
impl std::borrow::ToOwned for MyStr {
type Owned = MyString;
fn to_owned(&self) -> Self::Owned {
let s = self.as_str();
MyString::new(s.to_owned())
}
}
Borrow<T> は T 型の参照を取り出すためのトレイトである。
BorrowMut<T> は mutable 参照を取り出す版。
ToOwned は、参照型から所有権付きの型 (と値) を得るためのトレイトである。
Clone トレイトが実装されてさえいれば、 &T の所有権付きの型 T の値を .clone() によって得られる。
しかし [T]、 str や MyStr などのスライス型は DST であり Clone トレイトを実装できず、参照を外した型の値をそのまま保持できないから、代わりに何かしらのバッファ的な型が必要になる。
これは [T] の場合は Vec<T> であり、 str の場合は String であり、同様に MyStr に対しては MyString を用意してやろうということである。
同じようなコードになるが、一応 unsafe を使うことになるので AsciiStr のコード例も確認しておこう。
impl core::borrow::Borrow<AsciiStr> for AsciiString {
#[inline]
fn borrow(&self) -> &AsciiStr {
self.as_ascii_str()
}
}
impl core::borrow::BorrowMut<AsciiStr> for AsciiString {
#[inline]
fn borrow_mut(&mut self) -> &mut AsciiStr {
self.as_ascii_str_mut()
}
}
impl std::borrow::ToOwned for AsciiStr {
type Owned = AsciiString;
fn to_owned(&self) -> Self::Owned {
let s = self.as_str();
unsafe {
// SAFETY: Valid `AsciiStr` string is also valid as `AsciiString`.
AsciiString::new_unchecked(s.to_owned())
}
}
}
&AsciiStr から直接 AsciiString を作れないため &str と String を経由する。
これ自体は MyStr の例と同じだが、今回の例では String から AsciiString を作るのが unsafe な操作である。
不変条件を満たしていること自体は明らかなので、コメントで明示したうえで素直に書けばよい。
Default
所有権付きの独自型であれば Default トレイトは derive するなり自前実装するなりが簡単であるから、好きに実装すれば良い。
しかし実はそれ以外にも Default を実装できる対象がある。
独自スライス型の参照と可変参照、そして Box である。
impl Default for &MyStr {
fn default() -> Self {
MyStr::new(<&str>::default())
}
}
impl Default for &mut MyStr {
fn default() -> Self {
MyStr::new_mut(<&mut str>::default())
}
}
impl Default for Box<MyStr> {
#[inline]
fn default() -> Self {
<&MyStr>::default().into()
}
}
地味に便利なことに、 &'_ [T] や &'_ mut [T]、&'_ str、&'_ mut str 等の参照型には実は Default トレイトが実装されている。
もちろんこれらは長さ0の配列や文字列であるから、参照が指す値は特に有意義ということもない。
しかし str や [T] の strong typedef を定義しようというときにはこのトレイト実装自体が強力な道具となる。
なぜなら、 Default で作成できるこれらの参照は任意の lifetime で作ることができるため、どのような lifetime が要求されていても問題なく使える万能の参照だからである。
let a: &'static str = Default::default(); // OK!
let b: &'static mut MyStr = Default::default(); // OK!
'static さえ可能だし、 mutable な参照も作れる
Default トレイトはどんな場合にでも実装できるわけではないから、本当に妥当なデフォルト値があってそれが正しく用いられているかは確認すべきである。
impl Default for &AsciiStr {
fn default() -> Self {
unsafe {
// SAFETY: An empty string is valid ASCII string.
AsciiStr::new_unchecked(<&str>::default())
}
}
}
impl Default for &mut AsciiStr {
fn default() -> Self {
unsafe {
// SAFETY: An empty string is valid ASCII string.
AsciiStr::new_unchecked_mut(<&mut str>::default())
}
}
}
impl Default for Box<AsciiStr> {
#[inline]
fn default() -> Self {
<&AsciiStr>::default().into()
}
}
AsciiBytes の例は AsciiStr と同様になるので省略する。
PartialEq, PartialOrd
経験的に、これが一番面倒である。 面倒なので最後の方のセクションに持ってきた (最後に書くと楽とは言ってない)。 というか正直勘弁してほしいので、完全なコード例は諦めて概要とコード片だけで説明する。
まず、比較を独自に実装するとしても複数の方法がある。
-
内部の型と全く同じ比較を用いる
MyStr,AsciiStr,AsciiBytesは自然に作ればいずれもこの種類である。
-
独自スライス型同士では独自の比較を使い、独自スライスと内部の型では内部の型の比較を流用する
-
たとえば「URI 文字列型同士では正規化を行った結果で比較するが、 URI 文字列型と通常の文字列型では単純な文字列比較が行われる」など
Uri::new("http://example.com") == Uri::new("http://example.com:80/")かつUri::new("http://example.com") != "http://example.com:80/"ということ
- たとえば「独自スライス型の文字列は特定の文法に従っているので、一部分のみの比較で済む」などの場合
-
たとえば「URI 文字列型同士では正規化を行った結果で比較するが、 URI 文字列型と通常の文字列型では単純な文字列比較が行われる」など
-
すべての型に対して独自の比較を使う
-
たとえば rocket v0.4.6 クレートの
UncasedStrなど- これは比較の際に大文字・小文字の違いを無視する文字列型である。
-
たとえば rocket v0.4.6 クレートの
-
その他
- たとえば「同じ独自スライス型同士では通常と逆順 (つまり辞書式順序での降順) で比較され、その他の型との比較は許さない」など
どのような比較を定義するかは本当に用途と設計次第なので、私からアドバイスできることは何もない。 強いて言うなら、意味的にマトモな比較を実装しましょうとか、対称性・反対称性・推移性などの要求されている性質を満たすような実装にしましょう[11]とか、そんなところか。
PartialEq と PartialOrd の同時実装
特に独自スライス型においては、配列や文字列に似た性質を持っている場合が多く、 PartialEq と PartialOrd の両方を実装したくなる場合が多い。
このような実装はマクロである程度自動化できる。
/// Implement `PartialEq` and `Eq` for the given types.
macro_rules! impl_cmp {
($ty_lhs:ty, $ty_rhs:ty) => {
impl PartialEq<$ty_rhs> for $ty_lhs {
#[inline]
fn eq(&self, o: &$ty_rhs) -> bool {
<str as PartialEq<str>>::eq(AsRef::as_ref(self), AsRef::as_ref(o))
}
}
impl PartialOrd<$ty_rhs> for $ty_lhs {
#[inline]
fn partial_cmp(&self, o: &$ty_rhs) -> Option<core::cmp::Ordering> {
<str as PartialOrd<str>>::partial_cmp(AsRef::as_ref(self), AsRef::as_ref(o))
}
}
};
}
PartialEq と PartialOrd を同時に実装する例。
なお、比較アルゴリズムは str の比較に丸投げしている。
左右オペランドの交換
多くの場合、比較の左右オペランドを入れ替えても比較可能にしたいと思うことだろう。
たとえば MyStr == str が可能で str == MyStr が不可能というのはあまり素敵ではないし、実際遭遇すると割とフラストレーションが溜まる[12]。
こういう実装はさっさとマクロにするに限る。
/// Implement `PartialEq` and `Eq` symmetrically for the given types.
macro_rules! impl_cmp_symmetric {
($ty_lhs:ty, $ty_rhs:ty) => {
impl_cmp!($ty_lhs, $ty_rhs);
impl_cmp!($ty_rhs, $ty_lhs);
};
}
impl_cmp! マクロを用いた。
いくら書いても満たされることのない比較実装欲 (?)
たとえばこれらのマクロを使って MyStr に比較を実装しようとすると、こうなる。
impl_cmp_symmetric!(MyStr, str);
impl_cmp_symmetric!(MyStr, &str);
impl_cmp_symmetric!(&MyStr, str);
impl_cmp_symmetric!(MyStr, String);
impl_cmp_symmetric!(MyStr, &String);
impl_cmp_symmetric!(MyStr, Box<str>);
impl_cmp_symmetric!(Box<MyStr>, str);
impl_cmp_symmetric!(MyStr, Cow<'_, str>);
impl_cmp_symmetric!(MyString, &MyString);
impl_cmp_symmetric!(MyString, MyStr);
impl_cmp_symmetric!(MyString, &MyStr);
impl_cmp_symmetric!(MyString, str);
impl_cmp_symmetric!(MyString, &str);
impl_cmp_symmetric!(&MyString, str);
impl_cmp_symmetric! マクロを用いた。
残念ながら完全ではない。
不思議なことに、この比較というのがいくら実装しても後から足りないものが出てくるのである[13]。
特にありがちなのは、内側の型関係、所有権の有無関係、互換性のある別の型、 Box、 Rc、 Arc、 Cow、参照の有無、参照の mutability などなど。
本当にやっていられないので、気付いてから足すくらいの気持ちで良い。
おまけ: nostd, alloc 対応
組み込みなど制限された環境などでは std が使えなかったり、 alloc が使えなかったりする。 しかし独自スライス型だけであれば alloc が使えない環境でも利用可能なはずである[14]。 以下では、検査で alloc が必要ない場合にどの環境でどこまで実装できるかを簡単に紹介する。
| 機能 | 環境 | 註記 | ||
|---|---|---|---|---|
| core | alloc | std | ||
| 独自スライス型 | ○ | ○ | ○ | |
| 所有権付きスライス型 | △ | ○ | ○ |
所有権付きスライス型でアロケーションしなければ core 環境でも問題ない (たとえば内部の型として [u8; 6] を使うなど)。
ただし Cow と ToOwned は core 環境では使えない。
|
Box
|
× | ○ | ○ |
alloc::boxed::Box
|
Rc
|
× | ○ | ○ |
alloc::rc::Rc
|
Arc
|
× | ○ | ○ |
alloc::sync::Arc
|
Cow
|
× | ○ | ○ |
alloc::borrow::Cow
|
str
|
○ | ○ | ○ | 組み込み型 |
[T]
|
○ | ○ | ○ | 組み込み型 |
String
|
× | ○ | ○ |
alloc::string::String
|
Vec
|
× | ○ | ○ |
alloc::vec::Vec
|
エラー型への Error トレイト実装 |
× | × | ○ | std::error::Error は alloc に存在しない。
Error トレイトを実装せずともエラー型として使うことは可能なので、そこまで気にする必要はない。
|
From, TryFrom |
○ | ○ | ○ |
core::convert::{From, TryFrom}
|
FromStr
|
○ | ○ | ○ |
core::str::FromStr
|
AsRef, AsMut |
○ | ○ | ○ |
core::convert::{AsRef, AsMut}
|
Deref, DerefMut |
○ | ○ | ○ |
core::ops::{Deref, DerefMut}
|
Debug, Display |
○ | ○ | ○ |
core::fmt::{Debug, Display}
|
Borrow, BorrowMut |
○ | ○ | ○ |
core::borrow::{Borrow, BorrowMut}
|
ToOwned
|
× | ○ | ○ |
alloc::borrow::ToOwned
|
Default
|
○ | ○ | ○ |
core::default::Default
|
比較 (PartialEq, PartialOrd, Eq, Ord) |
○ | ○ | ○ |
core::cmp::{PartialEq, PartialOrd, Eq, Ord}
|
serde 対応 |
○ | ○ | ○ |
serde は (少なくとも v1.0.118 時点で既に) nostd / alloc 対応している。
alloc feature と std feature で制御できる。
|
どう対応すべきか
Cargo.toml
まず、 Cargo.toml で feature を宣言する。
[features]
default = ["std"]
alloc = []
std = ["alloc"]
std feature はデフォルトで有効にする慣習である。
std が使える環境では当然 alloc も使えるので、 std から alloc への依存を設定する。
これにより、「std または alloc が使える場合」という判定を単に「alloc が使える場合」で済ますことができる。
serde にも対応する場合に feature flag をどうすべきかは微妙である。
たぶんで定石はない。
たとえば alloc = ["serde/alloc"] などとしてしまうと serde feature を有効化していないのに alloc や std 環境で勝手に serde への依存が発生するなどという悲しいことになる。
ひとつの解決策は、諦めてバラバラのフラグにすることである。
[features]
default = ["std"]
alloc = []
std = ["alloc"]
serde-alloc = ["serde/alloc"]
serde-std = ["serde/std"]
[dependencies]
[dependencies.serde]
version = "1.0.118"
optional = true
default-features = false
features = ["derive"]
たぶんこれがいちばん無難だと思う。 根本的な問題は「特定の複数の feature が有効化されていたときのみ、別の特定の feature を有効化する」という指定の仕様が存在しないところであり、 cargo の仕様を変更せず知恵だけで綺麗に解決できるという類のものではなさそうである。 当面は workaround で誤魔化してやっていくしかない。
lib.rs
べつに main.rs でも良いのだが、ここまで面倒なことをするなら普通はライブラリにするだろうから、以後 lib.rs の前提でいく。
#![cfg_attr(not(feature = "alloc"), no_std)]
#[cfg(feature = "alloc")]
extern crate alloc;
ここでする必要があることは2つで、必要に応じて no_std attribute を有効にすること、必要に応じて extern crate alloc; することである。
#![cfg_attr(not(feature = "std"), no_std)]
まず、 std feature が有効化されていないとき、コンパイラに std ライブラリを使わないよう伝える。
これはクレート全体に反映されるべき設定なので #![] で書く。
#[cfg(feature = "alloc")]
extern crate alloc;
そして、 alloc feature が有効化されているとき、 alloc クレートが使えるようにする。
ここで cfg(feature = "alloc") という条件は次のアイテム extern crate alloc; にだけ指定したいものなので、 #[] で書く。
これらを間違うと、たとえば alloc feature が無効なときクレートの全ての内容がコンパイル結果から消え去ったりするので、タイプミスに注意。
std 環境では use なしに String や Vec 等が使えているが、これは std::prelude::v1 内のアイテムが自動で探索されることになっているからである。
しかし no_std な alloc 環境では、 prelude が使えない[15]。
このままでは alloc と std でできることはほとんど同じなのに書き分けが必要になってしまい、不便である。
これを解決するのが #[cfg(feature = "alloc")] extern crate alloc; である。
「alloc feature が有効化されているとき」というのが std が有効化されている場合も含むのがミソで、つまり std 環境でも同じ型がたとえば String (これは prelude 経由でアクセスできる std::string::String である) と alloc::string::String の2種類使えるようになるのである。
2種類のうち alloc で使える方を std でも常に使ってやることにすれば、 (Error トレイト以外では) 書き分けの必要がなくなる。
アイテムの参照
alloc と std に楽に対応する準備ができたわけだが、まずは core 環境で使えるものの書き方から確認していこう。
とはいっても、基本的に core 環境ではそこまで深く考えることはない。
std で参照していたアイテムパスを全て core から参照する くらいである。
たとえば use std::fmt; の代わりに use core::fmt; と書くとか、その程度のことである。
alloc と std の方は注意が必要で、やり方が2種類程度ある。
ひとつはファイル先頭で std の prelude 相当のものを alloc から事前に use する方法。
#[cfg(feature = "alloc")]
use alloc::{borrow::ToOwned, string::String};
この方法は、規模や使い方によっては手間がかかることがある。 というのも、何かが必要になってからいちいちファイル先頭に戻って編集する必要があったり、ファイルを複数に分割したとき unused import が大量発生する場合があったり、トレイト実装を別ファイルに異動したとき use の書き直しが必要だったりと、管理が面倒だからである。
もうひとつの方法は、アイテムを参照するときに毎回 alloc:: から始まるパスで参照すること。
#[cfg(feature = "alloc")]
impl alloc::borrow::ToOwned for AsciiStr {
type Owned = AsciiString;
fn to_owned(&self) -> Self::Owned {
let s = self.as_str();
unsafe {
// SAFETY: Valid `AsciiStr` string is also valid as `AsciiString`.
AsciiString::new_unchecked(s.to_owned())
}
}
}
ToOwned の実装例
要するに、いちいち alloc::borrow::ToOwned などのように指定してやれば、 std 用の prelude が利用可能か否かに関係なくアイテムを参照できるということである。
モジュール分割
alloc feature 有効時にしか有効化されるべきでない型定義やトレイト実装が多数あるわけだが、それらに毎度 #[cfg(feature = "alloc")] と付けていくのは面倒すぎる。
そこで、適当な子モジュールに吐き出してしまうと楽になる。
// ここに core 用の定義
#[cfg(feature = "alloc")]
mod owned {
// ここに alloc / std 用の定義
// `use alloc::string::String;` などしてもよい
}
このように条件付きでコンパイルされるコード群を別モジュールに吐き出すことで、 #[cfg(feature = "alloc")] を何度も書く必要がなくなり、可読性と保守性の向上が期待できる。
上の例ではインラインでモジュールを定義したが、もちろん別ファイルにしてもよい。
#[cfg(feature = "alloc")]
mod owned; // owned.rs 内に alloc / std 用の定義
// ここに core 用の定義
この辺りは規模と好みの問題だろう。 迷ったなら無難にファイルを分割するのが良いと思う。
おまけ: serde 対応
nostd 対応した状態で、加えて serde 対応を追加する例を提示する。
nostd 等を考えない場合は、単に std feature や alloc feature 関係の分岐等をなくして素直に std 環境用に書けば良いだけなので、例を参考に簡単に書けるだろう。
Cargo.toml
何はともあれ Cargo.toml からである。
[features]
default = ["std"]
alloc = []
std = ["alloc"]
serde-alloc = ["serde/alloc"]
serde-std = ["serde/std"]
[dependencies]
[dependencies.serde]
version = "1.0.118"
optional = true
default-features = false
features = ["derive"]
serde はデフォルトで std feature を有効化しているので、明示的な無効化のために default-features = false が必要である。
The
serdecrate has a Cargo feature named"std"that is enabled by default. In order to use Serde in a no_std context this feature needs to be disabled. Modify your Serde dependency in Cargo.toml to opt out of enabled-by-default features.
serde クレートのバージョンを指定するときは、特別な理由がなければ最新のバージョンを指定すること。
lib.rs
まず、必須ではないが便利な仕掛けとして、適切な serde の feature が有効化されていないときに、実際に serde を使っている場所よりも早い段階で lib.rs からエラーを出すことができる。
serde に String や Vec をサポートさせるには alloc か std feature を有効化する必要があり、 alloc はのところ nightly rustc が必要らしい。
#[cfg(all(
feature = "serde",
feature = "alloc",
not(feature = "std"),
not(any(feature = "serde-alloc", feature = "serde-std"))
))]
compile_error!(
"When both `serde` and `alloc` features are enabled,
`serde-alloc` or `serde-std` should also be enabled."
);
#[cfg(all(feature = "serde", feature = "std", not(feature = "serde-std")))]
compile_error!(
"When both `serde` and `std` features are enabled, `serde-std` should also be enabled."
);
構造としては、マズい組み合わせだった (具体的には、 feature が不足していた) ときに compile_error! マクロでメッセージとともにコンパイルエラーを発生させるという簡単なものである。
テキスト
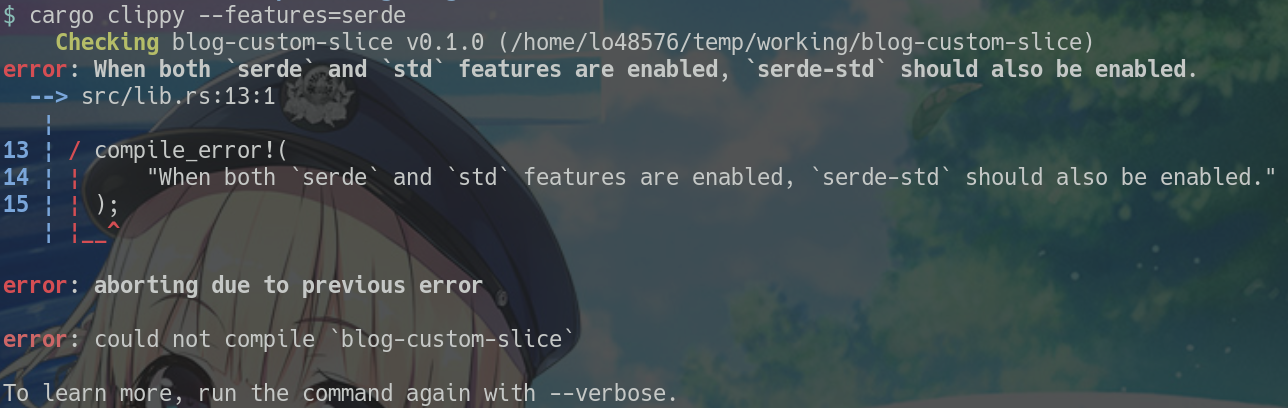
$ cargo clippy --features=serde Checking blog-custom-slice v0.1.0 (/home/lo48576/temp/working/blog-custom-slice) error: When both `serde` and `std` features are enabled, `serde-std` should also be enabled. --> src/lib.rs:13:1 | 13 | / compile_error!( 14 | | "When both `serde` and `std` features are enabled, `serde-std` should also be enabled." 15 | | ); | |__^ error: aborting due to previous error error: could not compile `blog-custom-slice` To learn more, run the command again with --verbose. $
compile_error! マクロのおかげで、エラーの根本的な原因が明確に提示できる
まず std 用の方から解説しよう。
#[cfg(all(feature = "serde", feature = "std", not(feature = "serde-std")))]
all() 内の条件指定のうち最初の2つ、 feature = "serde" と feature = "std" がそれぞれ「serde feature が有効である」と「std feature が有効である」という条件、最後の not(feature = "serde-std") が「serde-std feature が有効でない」という条件である。
all() は名前の通り「すべての条件が成り立っている」という条件である。
これらを組み合わせて、「serde と std feature が有効で、かつ serde-std feature が無効である場合」という条件になる。
compile_error!(
"When both `serde` and `std` features are enabled, `serde-std` should also be enabled."
);
compile_error! マクロは与えた文字列をエラーメッセージとして出力してコンパイルエラーを発生させる。
#[cfg(all(
feature = "serde",
feature = "alloc",
not(feature = "std"),
not(any(feature = "serde-alloc", feature = "serde-std"))
))]
alloc 用の条件は少々複雑だが、根本的には同じである。
std との違いは not(feature = "std") が追加されている点と、 not(feature = "serde-std") の代わりに not(any(feature = "serde-alloc", feature = "serde-std")) が指定されている点である。
not(feature = "std") は必須ではないが、これがないと std feature が有効なときまで alloc 環境用のメッセージが一緒に出てしまう。
これは std feature が自動的に alloc feature も有効化するよう Cargo.toml で設定したからである。
not(feature = "std") を条件に追加することで、 std が有効な場合を除外できる。
any() は「中の条件のひとつ以上が有効である」という条件である。
このことから not(any(feature = "serde-alloc", feature = "serde-std")) は文字通り「serde-alloc も serde-std も有効でない」という条件であるとわかる。
all(not(feature = "serde-alloc"), not(feature = "serde-std")) と書いても同じことであるが、 not() を複数回書くことになるので若干長くなり読みづらいかもしれない。
これで「serde と alloc feature が有効で、しかし std feature は有効でなく、また serde-alloc feature も serde-std feature も有効でない」という条件が指定できた。
compile_error!(
"When both `serde` and `alloc` features are enabled,
`serde-alloc` or `serde-std` should also be enabled."
);
残りはもう解説の必要はないだろう。 std 用のものをコピペしたきりメッセージを変え忘れたりしないよう注意しよう。 (←忘れていて首をひねったことがある顔)
serde::Serialize の実装
serialize は楽である。
内部の型と同じように扱ってよいのであれば、 #[derive(serde::Serialize)] と #[serde(transparent)] を指定するだけである。
/// My string.
#[repr(transparent)]
#[cfg_attr(feature = "serde", derive(serde::Serialize))]
#[cfg_attr(feature = "serde", serde(transparent))]
pub struct MyStr(str);
cfg_attr は、もし第1引数の条件が成立している場合は第2引数の attribute を有効化するというものである。
ここで誤って cfg_attr() でなく cfg() を使うと、型定義ごと無視されることになるので注意。
// **誤った定義例**
/// My string.
#[repr(transparent)]
// ↓ こうすると、 `serde` feature が無効なとき
// `derive(..)` どころでなく `MyStr` の型定義が無視される。
#[cfg(feature = "serde")]
#[derive(serde::Serialize)]
pub struct MyStr(str);
#[cfg(..)] は次の #[..] などではなく、アイテム (つまり型定義) 全体に適用される#[serde(transparent)] は、まさに strong typedef された型のための属性である。
その効果は、外側の包んでいる型の存在を無視して、 derive された Serialize や Deserialize の実装で内部の型を透過的に利用するというものである。
上の例では、 MyStr によって包まれているということを無視して str を読むのと同様な Serialize 実装を生やしてくれるようになる。
Serialize and deserialize a newtype struct or a braced struct with one field exactly the same as if its one field were serialized and deserialized by itself. Analogous to
#[repr(transparent)].
もし内部の型と別の形式でシリアライズしたいときは、素直に実装することになる。 serde の serialize は (deserialize と比べると) かなり簡単なので、実際のコードの例を載せておく。
/// String slice for a time in RFC 3339 [`full-time`] format, such as `12:34:56.7890-23:12`.
///
/// [`full-time`]: https://tools.ietf.org/html/rfc3339#section-5.6
#[derive(Debug, PartialEq, Eq, PartialOrd, Ord, Hash)]
#[repr(transparent)]
// Note that `derive(Serialize)` cannot used here, because it encodes this as
// `[u8]` rather than as a string.
//
// Comparisons implemented for the type are consistent (at least it is intended to be so).
// See <https://github.com/rust-lang/rust-clippy/issues/2025>.
// Note that `clippy::derive_ord_xor_partial_ord` would be introduced since Rust 1.47.0.
#[allow(clippy::derive_hash_xor_eq)]
#[allow(clippy::unknown_clippy_lints, clippy::derive_ord_xor_partial_ord)]
pub struct FullTimeStr([u8]);
/* 中略 */
#[cfg(feature = "serde")]
impl Serialize for FullTimeStr {
fn serialize<S>(&self, serializer: S) -> Result<S::Ok, S::Error>
where
S: serde::Serializer,
{
serializer.serialize_str(self.as_str())
}
}
FullTimeStr 型
(src/rfc3339/full_time.rs,
40–53行 (型定義),
558–566行 (実装))。
この型は ASCII 文字列ではあるが、内部処理の実装しやすさの都合で str でなく [u8] を内部の型として使っている。
serde::Deserialize の実装
残念ながら Deserialize の実装は面倒である。
所有権なしのスライス型
まず、独自スライス型等の DST については derive(serde::Deserialize) は不可能である。
なぜなら、 Deserialize は対象の型の値そのものを返すため、型のサイズがコンパイル時に判明していることを要求するからである。
仕方がないので手動で実装するほかない。
追加の制約なしの場合
#[cfg(feature = "serde")]
impl<'de> serde::Deserialize<'de> for &'de MyStr {
fn deserialize<D>(deserializer: D) -> Result<Self, D::Error>
where
D: serde::Deserializer<'de>,
{
use serde::de::Visitor;
/// Visitor for `&MyStr`.
struct StrVisitor;
impl<'de> Visitor<'de> for StrVisitor {
type Value = &'de MyStr;
#[inline]
fn expecting(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
f.write_str("a string")
}
#[inline]
fn visit_borrowed_str<E>(self, v: &'de str) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
Ok(Self::Value::from(v))
}
}
deserializer.deserialize_str(StrVisitor)
}
}
Deserialize 実装serde::Deserialize は serde::Serialize と同じく、 作りたい型に対して実装するトレイトである。
今回作りたい型は独自スライス型自体ではなく、その参照型である。
実際、上の例では MyStr 自体ではなく &MyStr に実装している。
参照型を作るとき serde への入力は可変でない参照として渡されるため、 &mut MyStr などへの実装はそもそも無理であり、考える必要はない。
#[cfg(feature = "serde")]
impl<'de> serde::Deserialize<'de> for &'de MyStr {
fn deserialize<D>(deserializer: D) -> Result<Self, D::Error>
where
D: serde::Deserializer<'de>,
{
serde にお決まりの形である。
詳しく考えたければ serde のドキュメントを参照した方が良いだろう。
serde::Deserialize<'de> の 'de は入力データの lifetime であるが、これが &'de MyStr のように出力の型に表れているということは、すなわち入力データを他の場所にコピーすることなくそのまま参照できる (その可能性がある) ということを意味している。
/// Visitor for `&MyStr`.
struct StrVisitor;
Deserialize の実装には、 visitor という役割を果たす値が必要になり、通常は専用の型を用意する。
これをモジュール直下に定義しても良いのだが、そうするとたったひとつの関数でしか使わない型がモジュールにぶち撒けられることになり、あまり気持ちよくない。
あるいは実装を他の場所に移そうとしたとき、一緒に移動し忘れる可能性もある。
そこで、今回定義する visitor である StrVisitor とそれへのトレイト実装は、 deserialize 関数内に書いてしまうことにする。
visitor は serde::de::Visitor が実装された型で、入力データの一部である何かしらの値について、その型やフィールド名等の情報を適切に利用して Rust 上の目的の型へと変換する。
詳細については公式ドキュメントを参照。
impl<'de> serde::de::Visitor<'de> for StrVisitor {
type Value = &'de MyStr;
今回実装する visitor は &'de MyStr を作るためのものだから、関連型 Value を &'de MyStr とする。
#[inline]
fn expecting(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
f.write_str("a string")
}
Visitor::expecting() は、 visitor が読もうとしている対象の型を端的に表現する文言を出力する。
読み込み失敗時に serde (deserializer) が「○○を読もうとしたけどだめだった」というエラーを返すが、この「○○」に該当する語句を出力するということである。
もし visitor が動的な情報や内部状態を持っていれば、たとえば write!(f, "an integer between {} and {}", self.min, self.max) のように write! マクロを使うのが楽かもしれない。
今回読みたい文字列型でそのような追加情報はないため、 Formatter::write_str で済ますことができる。
#[inline]
fn visit_borrowed_str<E>(self, v: &'de str) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
Visitor::visit_borrowed_str() を実装することで、「入力データと同じ lifetime を持つ文字列からであれば、所望の型の値を作れる」と表明する。
作ろうとしている &'de MyStr は入力データと同じ lifetime ('de) を持つ型なので、このメソッドを必ず実装する必要がある。
Visitor::visit_str() もあるが、これは「visit_str() 中のみ生きている文字列から、所望の型を作れる」という表明になる。
残念ながらこの場合、与えられた文字列は visit_str() 終了後に破棄が許されてしまうため、入力と同じ lifetime ('de) を与えることはできない。
よって、このメソッドはデフォルト実装でエラーを返させる。
Visitor::visit_string() についても同様に lifetime の不足の理由から手動での実装はしない。
// <StrVisitor as Visitor>::visit_borrowed_str() 内
Ok(Self::Value::from(v))
}
}
ここで Self::Value は <Self as serde::de::Visitor>::Value と等価で、すなわち &'de MyStr である。
つまり、 v: &'de str について From<&'a str> for &'a MyStr の実装を使うことで &'de MyStr の値を作成する。
&'de MyStr の作成は必ず成功するので、 Ok() で包んで返す。
// <&MyStr as Deserialize>::deserialize() 内
deserializer.deserialize_str(StrVisitor)
}
}
さて StrVisitor の定義ができたので、肝心の deserialize() の実装が書ける。
ここでは絶対に borrowed str しか受け付けない visitor を書いたため Deserializer::deserialize_str() を利用しているが、もし複数種類の入力を受け付けたいのであれば Deserializer::deserialize_any() を使うべきである (詳細は後述)。
最初からここで deserialize_any() を使っても問題なく動くので、コピペミスが怖かったりマクロで自動生成したいなどであればそのようにするのが良いかもしれない。
一応挙動の理解に参考になりそうなテストも載せておこう。 解説はしないので、詳しくは serde のドキュメントやリファレンスを漁ってほしい。
#[cfg(feature = "serde")]
#[cfg(test)]
mod serde_tests {
use super::*;
use serde::de::{
value::{BorrowedStrDeserializer, Error},
Deserialize, IntoDeserializer,
};
#[test]
fn deserialize_borrowed_str() {
let source_data = "hello";
let source_input = BorrowedStrDeserializer::<'_, Error>::new(source_data);
let mystr: &MyStr = <&MyStr>::deserialize(source_input).unwrap();
assert_eq!(mystr.as_str(), source_data);
}
#[test]
fn deserialize_owned_str() {
let source_input = "hello".to_owned().into_deserializer();
let result: Result<&MyStr, Error> = <&MyStr>::deserialize(source_input);
assert!(
result.is_err(),
"Deserialize is impossible when the source data does not have enough lifetime"
);
}
}
&MyStr は入力以下の生存期間しか持てないため、デシリアライズ完了とともに破棄される owned な文字列 ("hello".to_owned()) からは &MyStr を作ることができない
追加の制約ありで単一の型からしか読まない場合
#[cfg(feature = "serde")]
impl<'de> serde::Deserialize<'de> for &'de AsciiStr {
fn deserialize<D>(deserializer: D) -> Result<Self, D::Error>
where
D: serde::Deserializer<'de>,
{
/// Visitor for `&AsciiStr`.
struct StrVisitor;
impl<'de> serde::de::Visitor<'de> for StrVisitor {
type Value = &'de AsciiStr;
#[inline]
fn expecting(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
f.write_str("an ASCII string")
}
#[inline]
fn visit_borrowed_str<E>(self, v: &'de str) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
Self::Value::try_from(v).map_err(E::custom)
}
}
deserializer.deserialize_str(StrVisitor)
}
}
基本的に &MyStr の場合と同じであるが、値の作成に失敗する可能性があるため、その場合のエラー処理は追加されている。
// <StrVisitor as Visitor>::visit_borrowed_str() 内
Self::Value::try_from(v).map_err(E::custom)
Self::Value は &'de AsciiStr であるから <&'de AsciiStr as TryFrom>::try_from() で Result<&&'de AsciiStr, AsciiError> を得るが、 visit_borrowed_str() は Result<Self::Value, D::Error> を返すため、エラー型を変換してやる必要がある。
ここで D すなわち deserializer の型はデータ形式 (たとえば json 、たとえば toml) 次第なので、データ型にとって未知の型を想定する必要があり、 D: serde::Deserializer<'de> を頼りに Deserializer トレイト経由で操作するしかない。
問題のエラー型 D::Error は Deserializer::Error 関連型であるから、これも未知の型を想定して serde::de::Error 経由でしか操作が行えないようになっている。
serde::de::Error::custom() は汎用的なエラーを返すもので、雑に使うことができる (あまりよろしくないが)。
ちなみに serde::de::Error::custom() は渡されるメッセージに制約を課しているため、今回の例のような使い方をするなら本当は <AsciiError as core::fmt::Display>::fmt() で表示するメッセージもちゃんと調整する必要がある。
The message should not be capitalized and should not end with a period.
serde::de::Error::custom() のドキュメント
また、エラーをもっと正確に表現したいのであれば、 serde::de::Error の他のメソッドを使うことになる。
たとえば今回の例では、エラーの原因は型などではなく値の内容であるから、 serde::de::Error::invalid_value() を使って書くこともできる。
本当はこちらを使う方が望ましいかもしれない。
Self::Value::try_from(v)
.map_err(|_| E::invalid_value(serde::de::Unexpected::Str(v), &self))
追加の制約ありで複数の型から読む場合
AsciiBytes では、 &str からだけでなく &[u8] からもデシリアライズできるようにしよう。
#[cfg(feature = "serde")]
impl<'de> serde::Deserialize<'de> for &'de AsciiBytes {
fn deserialize<D>(deserializer: D) -> Result<Self, D::Error>
where
D: serde::Deserializer<'de>,
{
/// Visitor for `&AsciiBytes`.
struct BytesVisitor;
impl<'de> serde::de::Visitor<'de> for BytesVisitor {
type Value = &'de AsciiBytes;
#[inline]
fn expecting(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
f.write_str("ASCII bytes")
}
#[inline]
fn visit_borrowed_str<E>(self, v: &'de str) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
Self::Value::try_from(v).map_err(E::custom)
}
#[inline]
fn visit_borrowed_bytes<E>(self, v: &'de [u8]) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
Self::Value::try_from(v).map_err(E::custom)
}
}
deserializer.deserialize_any(BytesVisitor)
}
}
骨格はだいたい同じだが、重要な違いは次の2箇所だけである。
#[inline]
fn visit_borrowed_bytes<E>(self, v: &'de [u8]) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
Self::Value::try_from(v).map_err(E::custom)
}
まず、バイト列用の visit_borrowed_bytes() の実装を追加した。
これは visit_borrowed_str() の str でなく [u8] 版というだけなので、これ以上の説明は不要だろう。
// <BytesVisitor as Deserialize>::deserialize() 内
deserializer.deserialize_any(BytesVisitor)
それから、これまでの例では deserialize_str() を使っていたが、今回は deserialize_any() を使っている。
これは許容する型を単独で指定するのではなく、デシリアライザ (つまり読んでいるフォーマットについて知っている処理系) から型情報を受け取って、それに基いて値の作成を行うというものである。
今回の例では、たとえばデシリアライザがバイナリを読んだら BytesVisitor::visit_borrowed_bytes() が呼ばれ、文字列を読んだら BytesVisitor::visit_borrowed_str() が呼ばれるという挙動になる。
所有権付きの型
幸いなことに、所有権なしのスライス型の実装とほとんど変わらない。
From や TryFrom 等を実装しておいたおかげである。
まずは追加の制約なしの型から。
#[cfg(feature = "serde")]
impl<'de> serde::Deserialize<'de> for MyString {
fn deserialize<D>(deserializer: D) -> Result<Self, D::Error>
where
D: serde::Deserializer<'de>,
{
/// Visitor for `MyString`.
struct StringVisitor;
impl<'de> serde::de::Visitor<'de> for StringVisitor {
type Value = MyString;
#[inline]
fn expecting(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
f.write_str("a string")
}
#[inline]
fn visit_str<E>(self, v: &str) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
Ok(Self::Value::from(v))
}
#[inline]
fn visit_string<E>(self, v: String) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
Ok(Self::Value::from(v))
}
}
deserializer.deserialize_string(StringVisitor)
}
}
Deserialize を実装する
着目すべきなのは、 Visitor::Value の設定と、 visit_str() と visit_string() の両方を実装することくらいだろうか。
impl<'de> serde::de::Visitor<'de> for StringVisitor {
type Value = MyString;
当然ではあるが、今回返したいのは MyString なので、 Visitor トレイトの関連型もそのように設定する。
&'de MyStr のときと違って 'de が表れないのはポイントで、作られる値が入力の lifetime に非依存ということである。
すなわち、デシリアライズ後に即座に入力が破棄されても作られた値はそれ以上長く存在できるという、所有権付きの型に当然の性質が表れている。
#[inline]
fn visit_str<E>(self, v: &str) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
Ok(Self::Value::from(v))
}
#[inline]
fn visit_string<E>(self, v: String) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
Ok(Self::Value::from(v))
}
メソッドの中身については &MyStr の場合と同様だが、今回定義するメソッドは visit_str と visit_string である。
これらはいずれもデシリアライズ後すぐに入力が破棄されることを想定しており、デシリアライザが内部的に文字列デコードで String を使った場合は visit_string() が呼ばれ、 &str で済んだ場合であれば visit_str() が呼ばれる。
デシリアライザが内部的に String を使うというのは、たとえばエスケープの解除などが考えられる。
foo\"bar のような入力を foo"bar として解釈しなければならない場合、入力である foo\"bar をそのまま &str として visit_str() に渡されても困るわけである。
このように入力フォーマット特有の解釈や変換などの処理の過程で String を利用することがあり、 visitor が visit_string() を実装しているというのは「もしデシリアライザが所有権付きの文字列を持っていたら、所有権ごと渡してくれるとより効率的な処理ができます」という表明である。
visit_string() の実装は必須ではないが、実装しないことのメリットが皆無なので実装すべきである。
実装しなかった場合、デシリアライザが String を使っていても visit_str() に参照が渡される。
このとき Self::Value::from() つまり <MyString as From<&str>>::from は内部で動的にメモリを確保することになるので、デシリアライザが行った分と合わせて二度のアロケーションが発生しており非効率になってしまう。
追加の制約がある場合についても、所有権なしのスライス型を参考にいけるので、解説なしでコード例だけ載せておく。
#[cfg(feature = "serde")]
impl<'de> serde::Deserialize<'de> for AsciiString {
fn deserialize<D>(deserializer: D) -> Result<Self, D::Error>
where
D: serde::Deserializer<'de>,
{
/// Visitor for `AsciiString`.
struct StringVisitor;
impl<'de> serde::de::Visitor<'de> for StringVisitor {
type Value = AsciiString;
#[inline]
fn expecting(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
f.write_str("an ASCII string")
}
#[inline]
fn visit_str<E>(self, v: &str) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
Self::Value::try_from(v).map_err(E::custom)
}
#[inline]
fn visit_string<E>(self, v: String) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
Self::Value::try_from(v).map_err(E::custom)
}
}
deserializer.deserialize_string(StringVisitor)
}
}
Deserialize 実装
#[cfg(feature = "serde")]
impl<'de> serde::Deserialize<'de> for AsciiByteBuf {
fn deserialize<D>(deserializer: D) -> Result<Self, D::Error>
where
D: serde::Deserializer<'de>,
{
/// Visitor for `AsciiByteBuf`.
struct ByteBufVisitor;
impl<'de> serde::de::Visitor<'de> for ByteBufVisitor {
type Value = AsciiByteBuf;
#[inline]
fn expecting(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
f.write_str("ASCII bytes")
}
#[inline]
fn visit_str<E>(self, v: &str) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
Self::Value::try_from(v).map_err(E::custom)
}
#[inline]
fn visit_string<E>(self, v: String) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
Self::Value::try_from(v).map_err(E::custom)
}
#[inline]
fn visit_bytes<E>(self, v: &[u8]) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
Self::Value::try_from(v).map_err(E::custom)
}
#[inline]
fn visit_byte_buf<E>(self, v: Vec<u8>) -> Result<Self::Value, E>
where
E: serde::de::Error,
{
Self::Value::try_from(v).map_err(E::custom)
}
}
deserializer.deserialize_any(ByteBufVisitor)
}
}
Deserialize 実装
見た目には単調で情報量の薄いコードに見えるが、それは様々な型 (たとえば &str, String, &[u8], Vec<u8> など) に対して適切な From や TryFrom トレイトの実装を済ませてあるからであり、内部的に実行されるコードは少しずつ異なっている。
参考リンク
- メモリレイアウト関係
-
本記事の筆者による実用文字列型の実装例
iri-stringクレート-
型パラメータとして文法を定める規格を受け取るような、多相な文字列型を実装している
(例: 規格表現用
Specトレイト、RiAbsoluteStr文字列型、RiAbsoluteStr<IriSpec>の別名であるIriAbsoluteStr文字列型)。
-
型パラメータとして文法を定める規格を受け取るような、多相な文字列型を実装している
(例: 規格表現用
datetime-stringクレートxml-stringクレート